---
url: /fastapi_best_architecture_docs/index.md
---
::: center
# 金牌赞助商
:::
::: center
## 银牌赞助商
:::
::: center
## 贡献者
:::
---
---
url: /fastapi_best_architecture_docs/ai/llms.md
---
# LLMS.txt
本指南介绍如何让 Cursor、Windsurf 和 Claude 等 AI 工具更好地理解 fba
## 什么是 llms.txt?
我们支持通过 llms.txt 文件向大语言模型(llms)提供 fba 文档。此功能可帮助 AI 工具更好地理解我们的组件库、API 及使用模式
## 可用资源
我们提供多个 llms.txt 路由来帮助 AI 工具访问文档:
* [llms.txt](https://docs.fba.wu-clan.cc/fastapi_best_architecture_docs/llms.txt) - 包含所有组件及其文档链接的结构化概览
* [llms-full.txt](https://docs.fba.wu-clan.cc/fastapi_best_architecture_docs/llms-full.txt) - 提供包含实现细节和示例的完整文档
## 在 AI 工具中的使用
### Cursor
在 Cursor 中使用 @Docs 功能将 llms.txt 文件包含到您的项目中。这有助于 Cursor 为 fba 组件提供更准确的代码建议和文档
[详细了解 Cursor 中的 @Docs 功能](https://cursor.com/cn/docs/context/mentions#docs)
### Claude Code
在 Claude Code 中,将 llms.txt 添加到工作区的知识库(Docs / Context Files)配置中,即可在代码补全与解释时引用其中的内容,从而提升对
fba 组件的理解
[详细了解 Claude Code 文档上下文配置](https://code.claude.com/docs)
### Gemini CLI
在 Gemini CLI 中,可以通过 --context 参数或在 .gemini/config.json 中指定 llms.txt 文件路径,让 Gemini 在回答和生成代码时参考该文档
[详细了解 Gemini CLI 上下文配置](https://ai.google.dev/gemini-api/docs?hl=zh-cn)
## 其他 AI 工具
任何支持 llms.txt 的 AI 工具均可使用以上路径来更好地理解 fba
---
---
url: /fastapi_best_architecture_docs/ai/mcp.md
---
# MCP
[MCP 介绍](../blog/claude-ai-ecosystem.md){.read-more}
## ace (Augment Context Engine)
官网:[ace](https://www.augmentcode.com/context-engine)
相关文章:[linuxdo#1360514](https://linux.do/t/topic/1360514)
首当其冲的绝对是它,ace 绝对是无与伦比的存在,检索快,定位准;
但其存在国内账号注册难,订阅开通难,费用昂贵,易封号等多重机制,只能说是且用且珍惜
## fetch
源码:[fetch](https://github.com/modelcontextprotocol/servers/tree/main/src/fetch)
MCP 官方实现,使 LLM 能够从网页中检索和处理内容,并将 HTML 转换为 Markdown 以便于阅读和使用,虽然目前很多 LLM 已经内置 web
搜索引擎,但 fetch 仍可作为本级支持的一部分(免费)
## playwright
源码:[playwright-mcp](https://github.com/microsoft/playwright-mcp)
Playwright 是由微软(Microsoft)在 2020 年初开源的现代化 Web 测试与自动化框架,而 playwright-mcp 能够使 LLM
通过结构化的可访问性快照与网页进行交互,从而无需依赖屏幕截图或视觉调整后的模型
---
---
url: /fastapi_best_architecture_docs/ai/prompt.md
---
# Prompt
提示词不以多取胜,而是可用性,无效的提示词反而会给 LLM 带来负担
[Prompt 介绍](../blog/claude-ai-ecosystem.md){.read-more}
## 语言规范
```markdown
## Language norms
Thinking and executing are always in English, but replies are always in Chinese.
```
## 文件写入
```markdown
## File write
When writing too much file content at one time, always write in batches.
```
---
---
url: /fastapi_best_architecture_docs/ai/skills.md
---
# Skills
[Skills 介绍](../blog/claude-ai-ecosystem.md){.read-more}
## fba
[fba skill](https://skills.sh/fastapi-practices/skills/fba) 提供完整的架构规范、编码风格、插件开发指导
## antdv-next
[antdv-next skill](https://skills.sh/antdv-next/skills/antdv-next) Antdv Next Vue 3 组件库技能
---
---
url: /fastapi_best_architecture_docs/architecture.md
---
# 架构
待补充
---
---
url: /fastapi_best_architecture_docs/backend/deploy/Docker.md
---
# Docker 部署
::: info
一个还不错的教程网站:[Docker - 从入门到实践](https://yeasy.gitbook.io/docker_practice)
:::
## 本地部署
本地部署是为了能够快捷的提供本地 API 服务
### 后端
:::: steps
1. env
在 `backend` 目录打开终端,创建环境变量文件
```shell:no-line-numbers
touch .env
```
将初始化环境变量配置拷贝到环境变量文件中
```shell:no-line-numbers
cp .env.example .env
```
2. 按需修改配置文件 `backend/core/conf.py` 和 `.env`
3. 构建容器
在项目根目录中打开终端,执行以下命令
::: warning
如果容器要在本地启动,需要将 `.env` 中的 `127.0.0.1` 更改为 `host.docker.internal`
:::
::: tabs#dockerfile
@tab fba
```shell:no-line-numbers
docker build -f Dockerfile -t fba_server_independent .
```
@tab celery
```shell:no-line-numbers
docker build --build-arg SERVER_TYPE=celery -t fba_celery_independent .
```
:::
4. 启动容器
由于构建不包含数据库,请确保本地已安装并启动相关数据库(postgresql / mysql、redis)
::: tabs#dockerfile
@tab fba
```shell:no-line-numbers
docker run -d -p 8000:8000 --name fba_server fba_server_independent
```
@tab celery
```shell:no-line-numbers
docker run -d -p 8555:8555 --name fba_celery fba_celery_independent
```
:::
::::
### 前端
[**快速开始**](../../frontend/summary/quick-start.md){.read-more}
## 服务器部署
::: warning
\==此教程以 HTTPS 为例=={.warning}
fba 正在使用免费 SSL 证书:[httpsok-SSL](https://httpsok.com/p/4Qjd),证书自动续期,一行命令,轻松搞定 SSL
证书自动续签,支持:nginx、通配符证书、七牛云、腾讯云、阿里云、CDN、OSS、LB(负载均衡)
:::
### 后端
:::: steps
1. 拉取代码到服务器
将代码拉取到服务器通常采用 ssh 方式(更安全),当然你也可以选择使用 HTTPS 方式,具体方式请根据个人自行决定
2. env
在 `backend` 目录打开终端,创建环境变量文件
```shell:no-line-numbers
touch .env
```
进入 `deploy/backend/docker-compose` 目录,按需修改 `.env.server` 文件
::: info
我们在 docker-compose 脚本内通过挂载的方式使用 `.env.server` 文件作为 fba 环境变量文件,因此,本地修改此文件,将同步更新至
docker 容器,这意味着,修改环境变量将无需重新 build
:::
::: warning
如果您正在使用 MySQL 数据库,需修改 `.env.server` 部分配置如下:
```dotenv:no-line-numbers
# Database
DATABASE_TYPE='mysql'
DATABASE_HOST='fba_mysql'
DATABASE_PORT=3306
DATABASE_USER='root'
DATABASE_PASSWORD='123456'
```
:::
3. 按需修改配置文件 `backend/core/conf.py`
4. 更新 docker-compose 脚本
脚本 `docker-compose.yml` 中有相关注释说明,根据需要进行修改即可
5. 执行一键启动命令
在项目根目录中打开终端,执行以下命令
::: warning
命令执行期间遇到镜像拉取问题请自行 Google
:::
::: tabs
@tab 默认端口映射
```shell:no-line-numbers
docker compose up -d --build
```
@tab 自定义端口映射
```shell:no-line-numbers
docker compose --env-file deploy/backend/docker-compose/.env.docker up -d --build
```
:::
6. 等待命令执行完成
::::
### 前端
[**快速开始**](../../frontend/deploy/docker.md){.read-more}
## 注意事项
::: warning
不建议频繁使用 `docker compose up -d --build` 命令,此命令每次执行都会重新构建容器,并将原容器自动本地备份保留,这会导致硬盘空间迅速锐减
:::
[15 个 Docker 容器自动化管理的脚本](https://www.yuque.com/fcant/devops/itkfyytisf9z84y6){.read-more}
清理未使用的镜像
```shell:no-line-numbers
docker image prune
```
清理未使用的容器
```shell:no-line-numbers
docker container prune
```
清理所有未使用的镜像、容器、网络和构建缓存
```shell:no-line-numbers
docker system prune
```
---
---
url: /fastapi_best_architecture_docs/backend/deploy/legacy.md
---
# 传统部署
::: note
由于传统部署涉及修改的地方较多且较为复杂,因此无法提供此部署教程
您可以选择我们的 [专业版](../../pricing.md),以获取作者一对一部署指导
:::
@[bilibili](BV1q1KVe3E82)
---
---
url: /fastapi_best_architecture_docs/backend/ide/vscode.md
---
# vscode
[**Visual Studio Code** 官网](https://code.visualstudio.com/){.read-more}
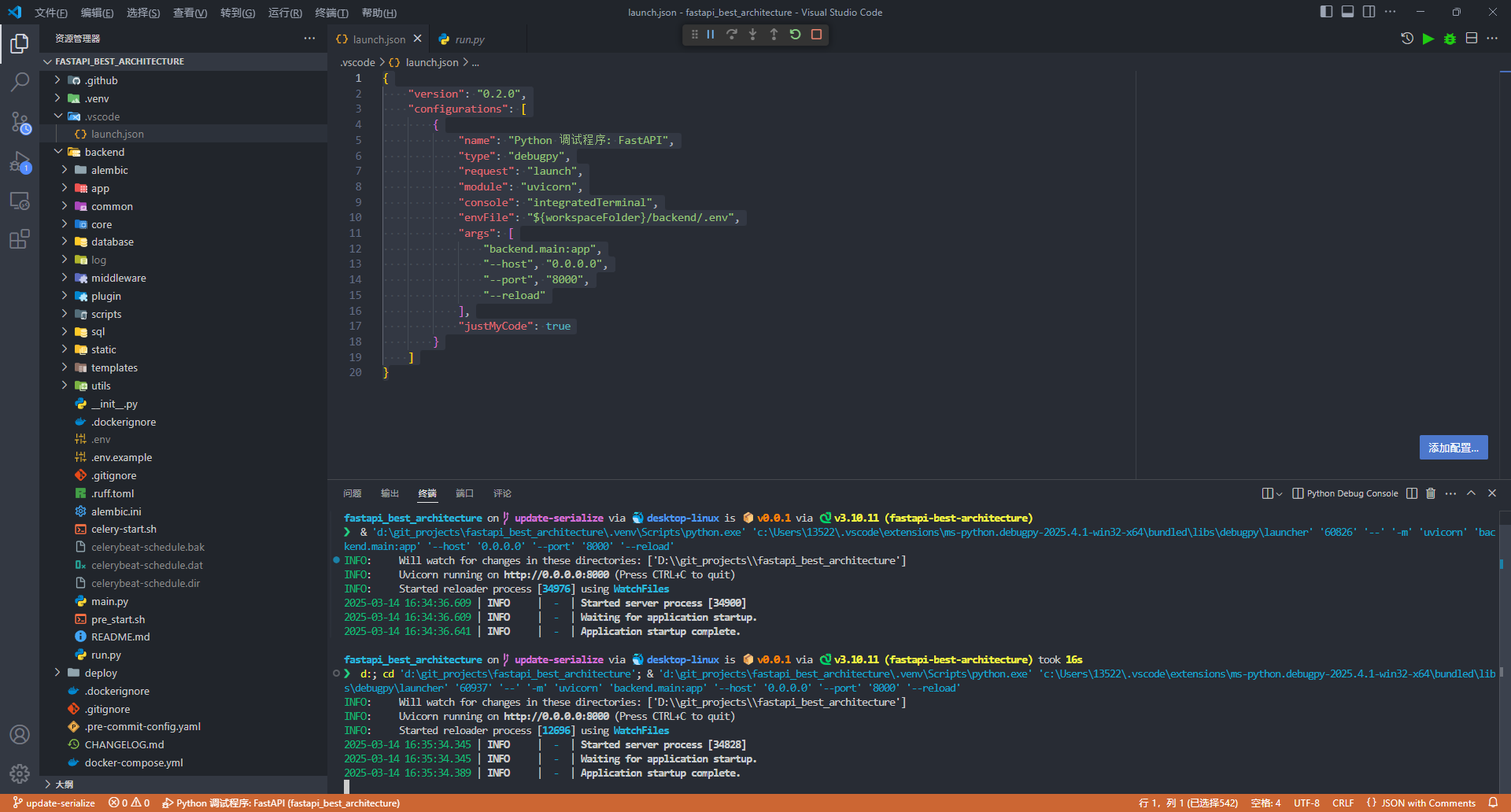
## DEBUG
如果你想在 vscode 中对 fba 进行调试,请创建 `.vscode/launch.json` 文件并添加以下配置
@[code json](../../code/launch.json5)
### 效果图
---
---
url: /fastapi_best_architecture_docs/backend/reference/apscheduler.md
---
# APScheduler
我们在最初的框架实现中,使用的是 APScheduler,但后来我们迁移到了
Celery,详情:[#225](https://github.com/fastapi-practices/fastapi_best_architecture/discussions/225)
FastAPI + APScheduler 现已作为独立仓库发行,它的优势在于易用性、灵活性和实时动态任务,如果你没有繁重的任务需求,它将是一个不错的选择
::: warning
我们计划将 APScheduler 制作为 fba
插件,但需要等待 [4.0](https://github.com/agronholm/apscheduler/issues/465#issuecomment-2818889743)
版本发布
:::
---
---
url: /fastapi_best_architecture_docs/backend/reference/cache.md
---
## 编程式缓存
* 完全手动控制缓存的读写、失效、TTL 等
* 适合复杂逻辑、批量操作、自定义序列化、事务等高级场景
* 代码较为显式,易于调试,但重复代码多,容易出错
### 依赖
所有操作都通过 `backend/database/redis.py` 中的全局 Redis 客户端完成:
```python
# 创建 redis 客户端单例
redis_client: RedisCli = RedisCli()
```
## 声明式缓存
* 通过装饰器自动管理缓存生命周期
* 代码极简,关注点分离,适合标准 CRUD
### @cached
自动缓存函数结果
```python
from backend.common.cache.decorator import cached
@cached(name="user:detail", key="user_id")
async def get_user_detail(user_id: int):
user = await User.get_or_none(id=user_id)
return user.dict() if user else None
```
* 第一次调用 → 执行函数 → 缓存结果
* 后续调用 → 直接从缓存(L1 或 Redis)返回
### @cache\_invalidate
方法执行后自动失效指定缓存
```python
from backend.common.cache.decorator import cache_invalidate
@cache_invalidate(name="user:detail", key="user_id")
async def update_user(user_id: int, name: str):
await User.filter(id=user_id).update(name=name)
return {"message": "updated"}
```
* 执行更新后 → 自动删除 L1 和 Redis 缓存
* 通过 Pub/Sub 广播 → 通知其他节点清理本地 L1 缓存
## 对比
| 维度 | 编程式缓存 | 声明式缓存(装饰器) |
|-------|---------------------------|--------------------|
| 代码量 | 多(每个地方都要写 get/set/delete) | 极少(一行装饰器即可) |
| 一致性保障 | 需手动保证(容易遗漏失效) | 自动处理 + Pub/Sub 广播 |
| 灵活性 | 最高 | 较高(支持 key\_builder) |
| 开发效率 | 较低 | 高 |
| 维护成本 | 高(修改逻辑需改多处) | 低(改装饰器参数即可) |
| 适用场景 | 复杂缓存策略、批量、预热、特殊数据 | 标准 CRUD、列表、详情、热点数据 |
| 调试难度 | 低(逻辑显式) | 中等(需理解装饰器内部流程) |
## 使用策略
大多数项目推荐以下模式:
* **特殊场景** → 使用编程式手动操作
* **读操作**(详情、列表、热点数据) → 使用 `@cached` 声明式缓存
* **删/改操作** → 使用 `@cache_invalidate` 声明式失效
* **开启本地缓存** → L1(内存)缓存将进一步提速,L2(Redis)作为持久层
* **追求开发效率和代码简洁** → 优先使用声明式缓存
* **需要精细控制、复杂逻辑** → 使用编程式缓存
---
---
url: /fastapi_best_architecture_docs/backend/reference/celery.md
---
# celery
Celery 对于绝大数人来讲,学习路线非常曲折,很难以理解其设计的复杂性,加上它不是很优雅的文档(当然,它很全面),让大多数人将其抛之脑后,今天,我们一起来打破障碍,拥抱
celery
## 为什么选择 Celery?
Celery 是一个基于 Python
开发的分布式任务队列系统,它在处理繁重计算或复杂任务具备极好的优势,因为它不会和主线程应用共享进程,而是在一个独立的进程中运行,这意味着,这些任务将被异步处理,而不会占用主线程应用的资源,这可以大大提高主应用程序的响应速度和吞吐量;你可以在我们的项目中找到迁移到
Celery 的相关讨论,请查看:[#225](https://github.com/fastapi-practices/fastapi_best_architecture/discussions/225)
## Broker(消息代理/中间件)
在 [Celery 词汇表](https://docs.celeryq.dev/projects/celery-enhancement-proposals/en/latest/glossary.html?highlight=broker)
中对 Broker 有以下描述:
> [企业集成模式 ](https://www.enterpriseintegrationpatterns.com/)
> 将 [消息代理 ](https://www.enterpriseintegrationpatterns.com/patterns/messaging/MessageBroker.html)
> 定义为一种架构构件,它可以接收来自多个目的地的
> [消息](https://docs.celeryq.dev/projects/celery-enhancement-proposals/en/latest/glossary.html?highlight=broker#term-Message)
> ,确定正确的目的地并将消息路由到正确的通道
在 Celery 中,我们可以将它视为存储已创建的调度任务并进行消息传递的桥梁,而它本身并不会执行任务;当任务被调度时,Broker
会存储调度任务消息,当 Worker 执行任务时,会从 Broker 调度任务消息中提取任务,因此,Broker 是 Celery 工作的重要组件
Celery 在文档 [后端和代码](https://docs.celeryq.dev/en/v5.4.0/getting-started/backends-and-brokers/index.html)
中列出了所支持的消息代理,fba 将通过 `ENVIRONMENT` 环境变量来自动选择使用 Redis 还是 *RabbitMQ*
```python
@model_validator(mode='before')
@classmethod
def validate_celery_broker(cls, values):
if values['ENVIRONMENT'] == 'prod':
# dev 环境默认使用 redis,如果是 prod 环境,则使用 rabbitmq
values['CELERY_BROKER'] = 'rabbitmq'
return values
```
## Worker
Worker 是调度任务的实际执行者,它从 Broker 中提取任务并执行,并且这是一种监听行为,当 Broker 接收调度信息后,Worker
就会提取任务并执行
如果没有 Worker 运行,调度任务消息会在 Broker 中积压,直到有 Worker 接收并执行
fba 支持通过 Docker 快捷的分布式扩容 Worker 数量:
```bash
docker-compose up -d --scale fba_celery_worker=3
```
## Backend
Celery 用户指南中的 [任务页面](https://docs.celeryq.dev/en/v5.4.0/userguide/tasks.html#result-backends) 对 Backend
有如下介绍:
> 如果你想跟踪任务或需要返回值,那么 Celery 必须将状态存储或发送到某个地方,以便日后检索。有几种内置的结果后端可供您选择:SQLAlchemy/Django
> ORM、Memcached、RabbitMQ/QPid (rpc) 和 Redis,您也可以定义自己的后端;没有哪种后端能很好地适用于每种使用情况。
> 您应该了解每个后端的优缺点,然后选择最适合您需求的后端
我们在 fba 中使用数据库作为默认存储后端
场景假设:跟踪异步任务的结果并返回结果
你正在构建一个耗时的生成测试报告的任务程序,为了在页面中直观的看到效果,你可以在前端项目中触发启动任务接口,FastAPI
收到请求后,触发 Celery 执行任务,此时,任务已经在 Celery 中执行,而不会阻塞 FastAPI 主应用,也不会占用 FastAPI
主应用资源,等待任务执行完成后,FastAPI 将返回任务结果,然后前端再对返回结果进行处理
在上述场景中,任务会将结果存储到 Backend,你可以在 Celery 状态文档中查看所有状态信息;Celery 执行任务并不强制要求使用
Backend,但是,如果你需要查看任务的结果,我们则推荐你这么做
## 优雅的集成
我们在 fba 中以非常优雅的方式集成了 Celery,你无需担心 Celery 苛刻的文件结构成本,只需通过简单的配置就可以轻松使用它,并且,我们支持直接创建异步函数的任务,
\==在 Celery6.0 版本之前,官网不提供异步函数支持==
进入源码 `backend/app` 目录,其中,task 目录就是我们的 Celery 应用程序,如果你不想使用它,而是使用其他任务应用,可以直接删除此文件夹
进入 task 目录后,其中 `celery.py` 是 Celery 的初始化文件,包含了启动 Celery
启动的参数配置,此文件无需进行任何修改,下面,我们将通过视频进行详细介绍:
@[bilibili](BV1KjkmYdE7q)
## 执行池
我们要根据实际情况为 worker 选择不同的执行池,目前推荐以下几种类型:
::: tabs
@tab prefork
任务涉及大量计算(如图像处理、数据计算等)
```bash
celery -A app.task.celery worker -l info -P prefork
```
@tab threads
不需要异步
```bash
celery -A app.task.celery worker -l info -P threads
```
@tab gevent
任务主要是 I/O 密集型且需要异步操作
```bash
celery -A app.task.celery worker -l info -P gevent
```
:::
## 并发数
celery 提供了 worker 并发数 `-c` 设置,参考如下:
::: tabs
@tab prefork
并发数建议设置为 CPU 核心数的 1 到 2 倍
@tab threads
并发数建议设置为 CPU 核心数的 2 到 10 倍
@tab gevent
并发数建议设置为 100 ~ 1000
:::
```bash
celery -A app.task.celery worker -l info -P gevent -c 1000
```
## 队列
celery 提供了 `queue`(队列),我们可以在 celery 配置中添加如下代码:
```python
app.conf.task_queues = (
Queue('cpu_bind', routing_key='cpu'), # cpu 密集型绑定队列
Queue('io_bind', routing_key='io'), # io 密集型绑定队列
Queue('all_in'), # 无路由键的简单队列
)
```
启动 worker 时,需要添加 `-Q` 参数指定队列进行启动,例如:
```bash
celery -A app.task.celery worker -l info -P gevent -c 1000 -Q cpu_bind # 启动 cpu worker
celery -A app.task.celery worker -l info -P gevent -c 1000 -Q io_bind # 启动 io worker
```
接下来,我们就可以像下面这样在任务定义的时候指定队列运行任务了
```python
@celery_app(queue='io_bind')
async def io_bind_task():
...
```
---
---
url: /fastapi_best_architecture_docs/backend/reference/cli.md
---
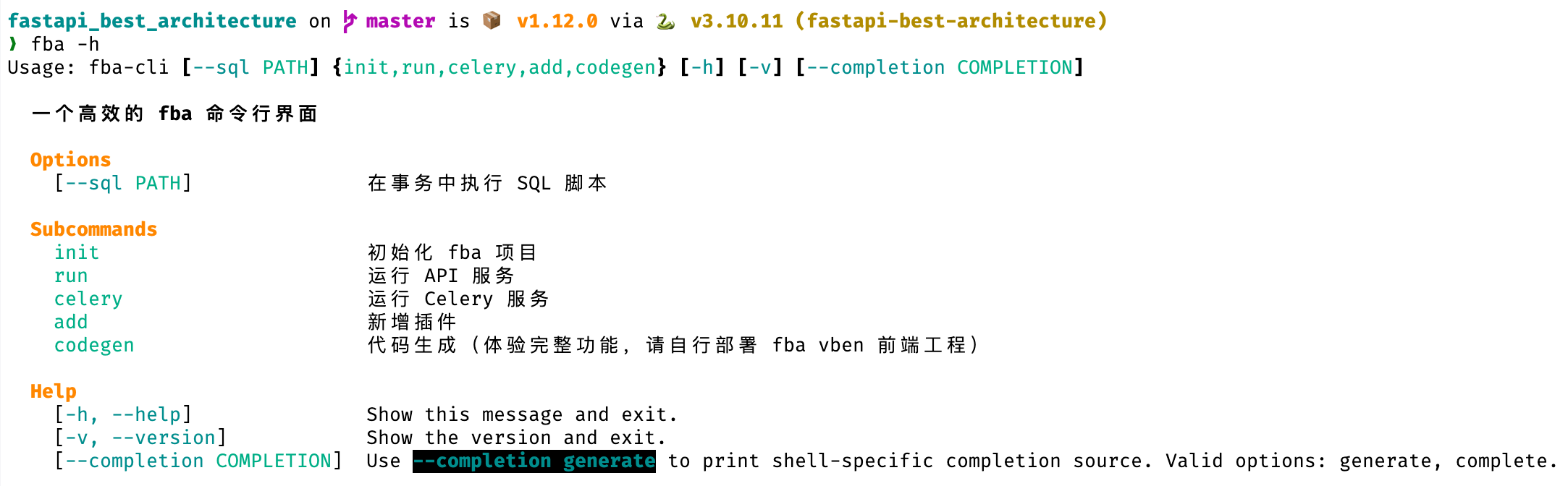
# CLI
fba 内置了便利的 CLI 支持,安装依赖后,尝试在终端输入 `fba -h` 或 `fba --help` 以查看更多信息
::: demo-wrapper img
:::
---
---
url: /fastapi_best_architecture_docs/backend/reference/code-generation.md
---
# 代码生成
::: tip
此功能当前仅适用于后端工程,不包含前端代码
:::
::: warning
API 调用无法直观的预览代码生成结果,它必须配合前端项目使用,请查看查看 [效果预览](#效果预览)
:::
## 概念
代码生成器使用 api 调用实现,包含【业务】和【模型】两个模块
### 业务
包含代码生成的相关配置,详情请查看:`backend/plugin/code_generator/model/gen_business.py`
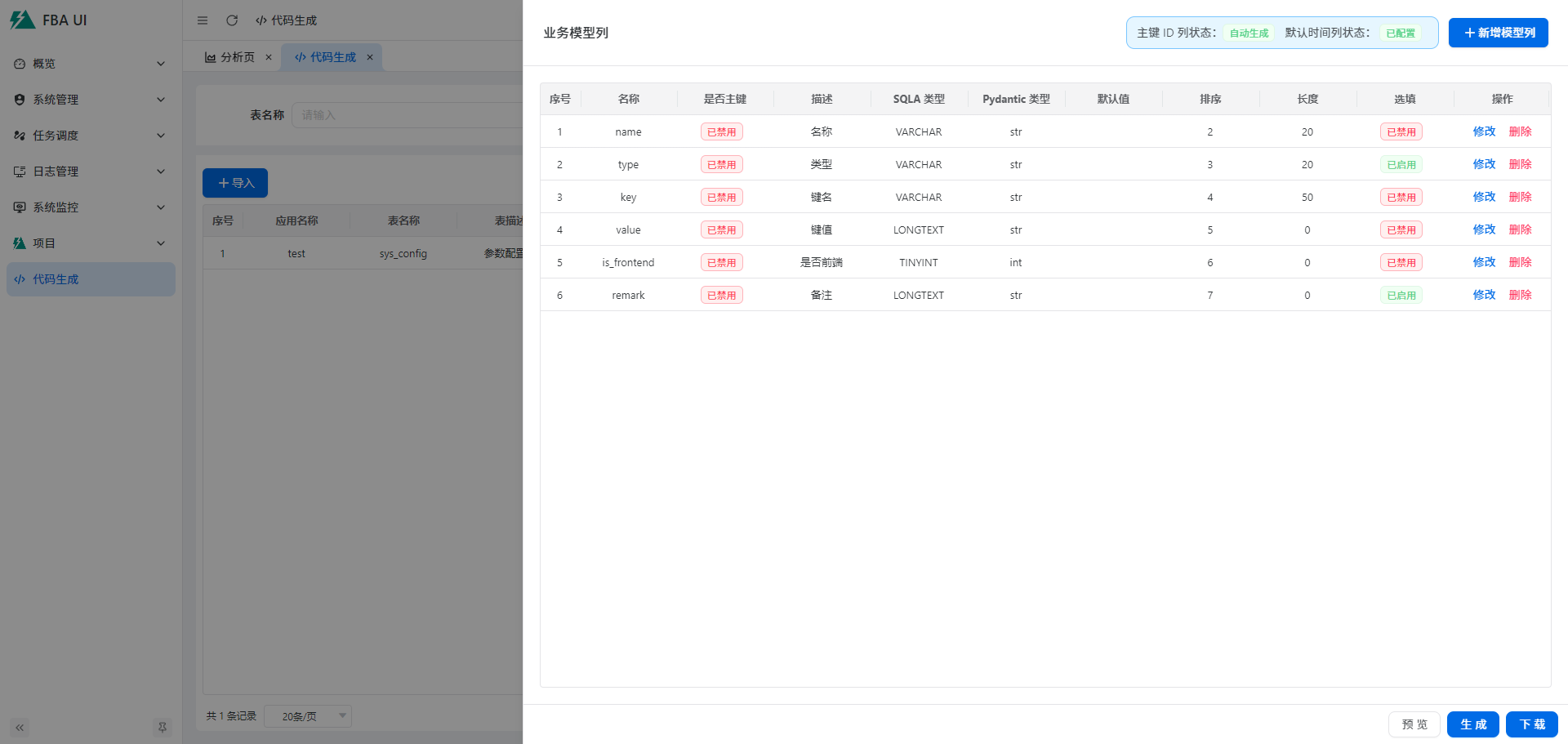
### 模型
包含代码生成所需要的模型列信息,就像正常定义模型列一样,目前支持的功能有限
## 使(食)用
1. 启动后端服务,打开 swagger 文档直接操作
2. 通过第三方 api 调试工具发送接口请求
3. 同时启动前后端,从页面进行操作
接口参数基本都有说明,请注意查看
### F. 纯手动模式
不推荐(手动创建业务接口被标记为「已弃用」)
1. 通过创建业务接口手动添加一项业务数据
2. 通过模型创建接口手动添加模型列
3. 访问预览、磁盘写入、下载接口,执行代码生成相应工作
### S. 自动模式
推荐
1. 访问 `tables` 接口,获取数据库表名列表
2. 通过 `imports` 接口,导入数据库已有的数据库表数据(将自动创建业务表数据和模型表数据)
3. 访问预览、磁盘写入、下载接口,执行代码生成相应工作
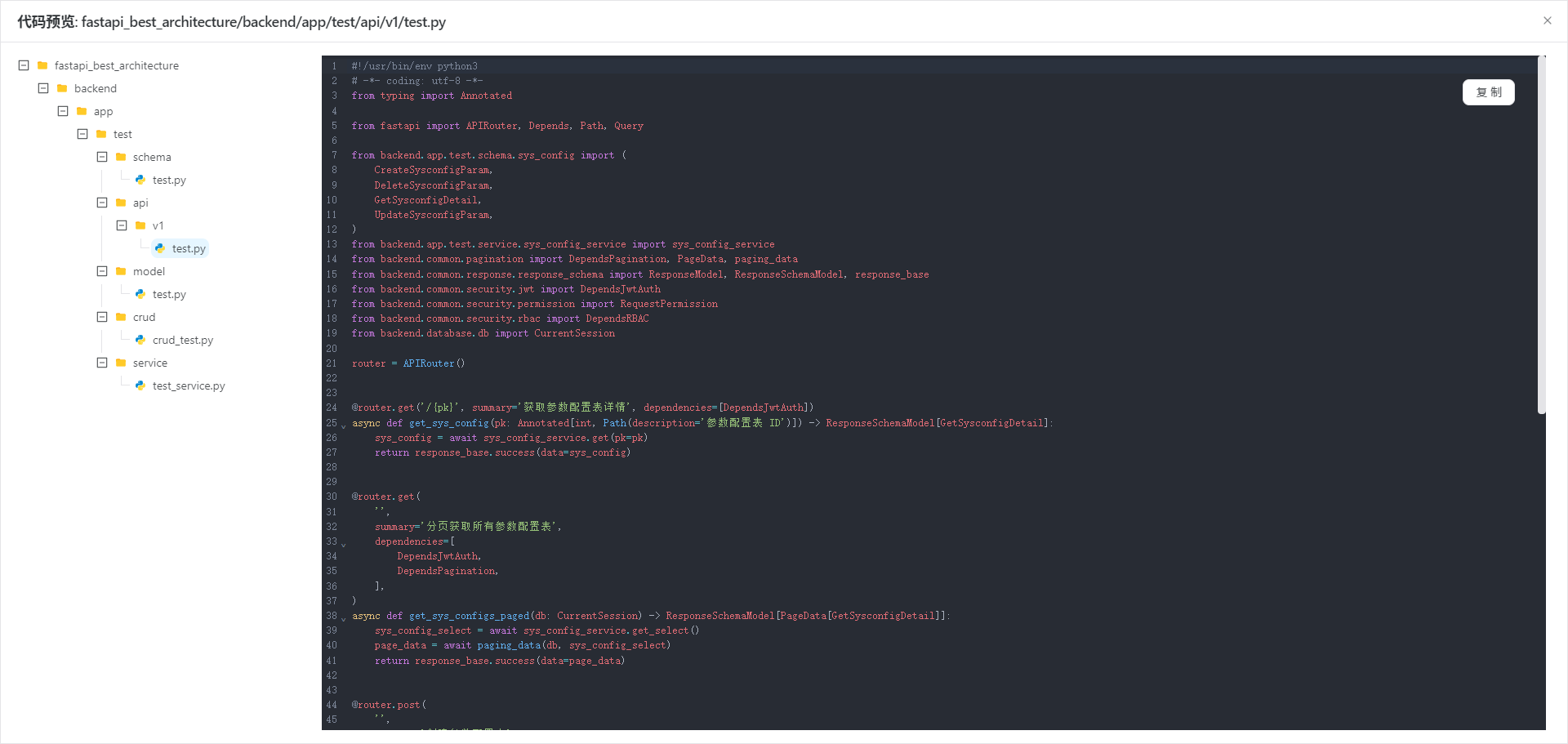
## 效果预览
---
---
url: /fastapi_best_architecture_docs/backend/reference/conf.md
---
# 配置
fba 配置文件位于 `backend/core/conf.py`
,所有应用和插件的配置都应统一放置在此文件内,包含 标签的配置默认为环境变量配置
## 环境配置
### `ENVIRONMENT`
指定环境模式,当设置为 `prod` 时,openapi 相关在线文档将被禁止访问
## FastAPI 配置
### `FASTAPI_API_V1_PATH`
API 版本号配置
### `FASTAPI_TITLE`
openapi 相关在线文档标头配置
### `FASTAPI_DESCRIPTION`
openapi 相关在线文档描述信息
### `FASTAPI_DOCS_URL`
docs 在线文档地址
### `FASTAPI_REDOC_URL`
redoc 在线文档地址
### `FASTAPI_OPENAPI_URL`
openapi JSON 数据在线地址
### `FASTAPI_STATIC_FILES`
是否开启 FastAPI 静态文件服务
## 数据库配置
### `DATABASE_TYPE`
数据库类型,仅支持 `postgresql` 和 `mysql`,需注意第三方插件兼容性
### `DATABASE_HOST`
数据库的主机地址
### `DATABASE_PORT`
数据库的端口号
### `DATABASE_USER`
数据库用户名
### `DATABASE_PASSWORD`
数据库认证密码
### `DATABASE_ECHO`
是否输出 sqlalchemy 操作日志
### `DATABASE_POOL_ECHO`
是否输出 sqlalchemy 线程池操作日志
### `DATABASE_SCHEMA`
需要连接的数据库
### `DATABASE_CHARSET`
数据库字符集,仅用于 mysql
### `DATABASE_PK_MODE`
数据库主键模式,更多详情:[切换主键](./pk.md)
::: caution
不要随意更新此配置!!!否则将导致致命问题!!!
:::
## Redis 配置
### `REDIS_TIMEOUT`
Socket 读写操作的超时时间和 Redis 建立 TCP 连接时的超时时间
### `REDIS_HOST`
Redis 服务器的主机地址
### `REDIS_PORT`
Redis 服务器的端口号
### `REDIS_PASSWORD`
Redis 认证密码
### `REDIS_DATABASE`
全局默认使用的 Redis 逻辑数据库索引(0 - 15)
## Snowflake(雪花算法)
### `SNOWFLAKE_DATACENTER_ID`
雪花算法数据中心 ID
### `SNOWFLAKE_WORKER_ID`
雪花算法工作机器 ID
::: warning
`SNOWFLAKE_DATACENTER_ID` 和 `SNOWFLAKE_WORKER_ID` 仅允许同时非 None 或同时为 None
同时非 None 时,雪花算法将应用此配置(适用于单机单进程场景)
同时为 None 时,雪花算法将自动分配此配置(适用于多线程,多进程,分布式等场景)
:::
### `SNOWFLAKE_REDIS_PREFIX`
雪花算法配置存储到 Redis 时的前缀
### `SNOWFLAKE_HEARTBEAT_INTERVAL_SECONDS`
雪花算法配置存储到 Redis 后的心跳检测间隔时间(秒)
::: warning
此配置不应大于 `SNOWFLAKE_NODE_TTL_SECONDS`
:::
### `SNOWFLAKE_NODE_TTL_SECONDS`
雪花算法配置存储到 Redis 时的生存时间(秒)
## Token 配置
### `TOKEN_SECRET_KEY`
token 生成和解析密钥,用于防止 token 被恶意篡改,密钥生成:`secrets.token_urlsafe(32)`
::: danger
请妥善保管此值,以免遭受恶意攻击
:::
### `TOKEN_ALGORITHM`
token 加密算法
### `TOKEN_EXPIRE_SECONDS`
token 过期时长(秒)
### `TOKEN_REFRESH_EXPIRE_SECONDS`
刷新 token 过期时长(秒)
### `TOKEN_REDIS_PREFIX`
token 存储到 Redis 时的前缀
### `TOKEN_EXTRA_INFO_REDIS_PREFIX`
token 扩展信息存储到 Redis 时的前缀
### `TOKEN_ONLINE_REDIS_PREFIX`
token 在线状态存储到 Redis 时的前缀
### `TOKEN_REFRESH_REDIS_PREFIX`
刷新 token 存储到 Redis 时的前缀
### `TOKEN_REQUEST_PATH_EXCLUDE`
JWT / RBAC 路由白名单,在此配置内的请求地址将不会校验 token 的真伪性
::: warning
fba 内通过 JWT 中间件解析 token 获取用户信息,并将用户信息赋值给 FastAPI request 对象,如果路由包含在此配置中,
`request.user` 将不可用
:::
### `TOKEN_REQUEST_PATH_EXCLUDE_PATTERN`
JWT / RBAC 路由白名单正则模式,从路由头部开始匹配,与之匹配的请求地址将不会校验 token 真伪性,注意项同上
## 用户安全配置
### `USER_LOCK_REDIS_PREFIX`
用户锁定存储到 Redis 时的前缀
### `USER_LOCK_THRESHOLD`
用户密码错误锁定阈值,0 表示禁用锁定
### `USER_LOCK_SECONDS`
用户锁定时长(秒)
### `USER_PASSWORD_EXPIRY_DAYS`
用户密码有效期,0 表示永不过期
### `USER_PASSWORD_REMINDER_DAYS`
用户密码到期提醒,0 表示不提醒
### `USER_PASSWORD_HISTORY_CHECK_COUNT`
用户密码历史检查数量,避免重复使用历史密码
### `USER_PASSWORD_MIN_LENGTH`
用户密码最小长度
### `USER_PASSWORD_MAX_LENGTH`
用户密码最大长度
### `USER_PASSWORD_REQUIRE_SPECIAL_CHAR`
用户密码需要特殊字符
## 登录配置
### `LOGIN_CAPTCHA_REDIS_PREFIX`
登录验证码存储到 Redis 时的前缀
### `LOGIN_CAPTCHA_EXPIRE_SECONDS`
登录验证码过期时长(秒)
### `LOGIN_CAPTCHA_ENABLED`
是否开始登录验证码
### `LOGIN_FAILURE_PREFIX`
登录失败存储到 Redis 时的前缀
## JWT 配置
### `JWT_USER_REDIS_PREFIX`
JWT 中间件存储用户信息到 Redis 时的前缀
## RBAC 配置
[更多详情](./RBAC.md){.read-more}
### `RBAC_ROLE_MENU_MODE`
是否开启 RBAC 角色菜单模式
### `RBAC_ROLE_MENU_EXCLUDE`
开启 RBAC 角色菜单模式时,跳过 RBAC 鉴权的标识(当接口权限标识和用户菜单权限标识相同时)
## Cookie 配置
### `COOKIE_REFRESH_TOKEN_KEY`
将刷新 token 存储到 cookie 时的键名
### `COOKIE_REFRESH_TOKEN_EXPIRE_SECONDS`
将刷新 token 存储到 cookie 时的过期时长(秒)
## 数据权限配置
### `DATA_PERMISSION_COLUMN_EXCLUDE`
排除允许进行数据过滤的 SQLA 模型列,例如 id, password 等
## Socket.IO 配置
### `WS_NO_AUTH_MARKER`
连接 socket.io 服务时跳过用户验证的标记
::: danger
请妥善保管此值,以免遭受恶意攻击
:::
## CORS 配置
### `CORS_ALLOWED_ORIGINS`
跨域请求时允许的来源,末尾不带 `/`,例如:`http//127.0.0.1:8000`
### `CORS_EXPOSE_HEADERS`
跨域公开标头,允许将此标头添加到请求标头中
## 中间件配置
### `MIDDLEWARE_CORS`
是否启用跨域中间件
## 请求限制配置
### `REQUEST_LIMITER_REDIS_PREFIX`
记录请求频率信息到 Redis 时的前缀
## 时间配置
### `DATETIME_TIMEZONE`
全局时区
### `DATETIME_FORMAT`
将时间转为时间字符串的格式
## 文件上传配置
::: warning
部分配置可能被 nginx 覆盖
:::
### `UPLOAD_READ_SIZE`
上传文件时,每次读取文件内容的缓冲大小
### `UPLOAD_IMAGE_EXT_INCLUDE`
允许上传的图片文件类型
### `UPLOAD_IMAGE_SIZE_MAX`
允许上传的图片文件最大尺寸
### `UPLOAD_VIDEO_EXT_INCLUDE`
允许上传的视频文件类型
### `UPLOAD_VIDEO_SIZE_MAX`
允许上传的视频文件最大尺寸
## 演示模式配置
### `DEMO_MODE`
是否开启演示模式,开启时,仅允许访问 `GET` 和 `OPTIONS` 请求
### `DEMO_MODE_EXCLUDE`
开启演示模式时,不进行请求限制的接口
## IP 定位配置
### `IP_LOCATION_PARSE`
请求发起者的定位信息获取模式
### `IP_LOCATION_REDIS_PREFIX`
定位信息存储到 Redis 时的前缀
### `IP_LOCATION_EXPIRE_SECONDS`
定位信息缓存时长(秒)
## Trace ID
### `TRACE_ID_REQUEST_HEADER_KEY`
跟踪 ID 请求头键名
### `TRACE_ID_LOG_LENGTH`
跟踪 ID 日志长度,必须小于等于 32
### `TRACE_ID_LOG_DEFAULT_VALUE`
跟踪 ID 日志默认值
## 日志
### `LOG_FORMAT`
日志内容格式(控制台和文件同享)
## 日志(控制台)
### `LOG_STD_LEVEL`
日志记录级别
## 日志(文件)
### `LOG_FILE_ACCESS_LEVEL`
访问日志记录级别
### `LOG_FILE_ERROR_LEVEL`
错误日志记录级别
### `LOG_ACCESS_FILENAME`
访问日志文件名
### `LOG_ERROR_FILENAME`
错误日志文件名
## 操作日志
### `OPERA_LOG_PATH_EXCLUDE`
操作日志路径排除,在此配置内的请求地址不会记录操作日志
### `OPERA_LOG_ENCRYPT_KEY_INCLUDE`
加密操作日志中的接口请求参数
### `OPERA_LOG_QUEUE_BATCH_CONSUME_SIZE`
操作日志队列批量消费大小,达到上限后,操作日志将批量写入数据库
### `OPERA_LOG_QUEUE_TIMEOUT`
操作日志队列超时时长,达到上限后,操作日志将批量写入数据库
## 插件配置
### `PLUGIN_PIP_CHINA`
通过 pip 下载插件依赖时,是否使用国内源
### `PLUGIN_PIP_INDEX_URL`
通过 pip 下载插件依赖时的索引地址
### `PLUGIN_PIP_MAX_RETRY`
pip 下载最大重试次数
### `PLUGIN_REDIS_PREFIX`
插件信息存储到 Redis 时的前缀
## I18n 配置
### `I18N_DEFAULT_LANGUAGE`
国际化响应的默认语言
## Grafana 配置
### `GRAFANA_METRICS`
是否启用 Grafana 套件
::: warning
如果不需要可观测性集成,不建议启用此功能
:::
### `GRAFANA_APP_NAME`
Grafana 应用名称,通常情况下,不建议修改
### `GRAFANA_OTLP_GRPC_ENDPOINT`
Grafana OTLP 协议 grpc 地址,用于发送遥测数据
## 应用:Task
### `CELERY_BROKER_REDIS_DATABASE`
Celery 代理使用的 Redis 逻辑数据库
### `CELERY_RABBITMQ_HOST`
Celery 连接 RabbitMQ 服务的主机地址
### `CELERY_RABBITMQ_PORT`
Celery 连接 RabbitMQ 服务的主机端口号
### `CELERY_RABBITMQ_USERNAME`
Celery 连接 RabbitMQ 服务的用户名
### `CELERY_RABBITMQ_PASSWORD`
Celery 连接 RabbitMQ 服务的密码
### `CELERY_BROKER`
Celery 代理模式(开发模式默认使用 Redis,线上模式强制切换为 Rabbitmq)
### `CELERY_RABBITMQ_VHOST`
Celery 连接 RabbitMQ 服务的 vhost
### `CELERY_REDIS_PREFIX`
Celery 数据存储到 Redis 时的前缀
### `CELERY_TASK_MAX_RETRIES`
Celery 任务执行失败时的最大重试次数
## 插件:Code Generator
### `CODE_GENERATOR_DOWNLOAD_ZIP_FILENAME`
下载代码时的 ZIP 压缩包文件名
## 插件:OAuth2
### `OAUTH2_GITHUB_CLIENT_ID`
GitHub 客户端 ID
### `OAUTH2_GITHUB_CLIENT_SECRET`
GitHub 客户端密钥
### `OAUTH2_GOOGLE_CLIENT_ID`
Google 客户端 ID
### `OAUTH2_GOOGLE_CLIENT_SECRET`
Google 客户端密钥
### `OAUTH2_LINUX_DO_CLIENT_ID`
Linux Do 客户端 ID
### `OAUTH2_LINUX_DO_CLIENT_SECRET`
Linux Do 客户端密钥
### `OAUTH2_STATE_REDIS_PREFIX`
OAuth2 状态信息存储到 Redis 时的前缀
### `OAUTH2_STATE_EXPIRE_SECONDS`
OAuth2 状态信息存储到 Redis 时的过期时间(秒)
### `OAUTH2_GITHUB_REDIRECT_URI`
GitHub 重定向地址,必须与 GitHub OAuth Apps 配置保持一致
### `OAUTH2_GOOGLE_REDIRECT_URI`
Google 重定向地址,必须与 Google OAuth 2.0 客户端配置保持一致
### `OAUTH2_LINUX_DO_REDIRECT_URI`
Linux Do 重定向地址,必须与 Linux Do Connect 配置保持一致
### `OAUTH2_FRONTEND_LOGIN_REDIRECT_URI`
登陆成功后,重定向到前端的地址
### `OAUTH2_FRONTEND_BINDING_REDIRECT_URI`
绑定成功后,重定向到前端的地址
## 插件:Email
### `EMAIL_USERNAME`
电子邮箱发件用户
### `EMAIL_PASSWORD`
电子邮箱发件用户密码
### `EMAIL_HOST`
电子邮箱服务主机地址
### `EMAIL_PORT`
电子邮箱服务主机端口号
### `EMAIL_SSL`
发送电子邮件时,是否开启 SSL
### `EMAIL_CAPTCHA_REDIS_PREFIX`
电子邮件验证码存储到 Redis 时的前缀
### `EMAIL_CAPTCHA_EXPIRE_SECONDS`
电子邮件验证码缓存时长(秒)
---
---
url: /fastapi_best_architecture_docs/backend/reference/CORS.md
---
当进行前后端项目联调或服务器部署时,你通常会遇到跨域问题,不过没关系,你只需进入 `core/conf.py` 文件,修改
`CORS_ALLOWED_ORIGINS` 配置即可,就可以轻松解决 CORS 相关问题
## 本地
```py
CORS_ALLOWED_ORIGINS: list[str] = [
'http://localhost:5173', # 前端访问地址,末尾不带 '/'
]
```
## 服务器
::: code-tabs
@tab HTTP
```py
# [!code word:http]
CORS_ALLOWED_ORIGINS: list[str] = [
'http://服务器ip:端口号', # 前端访问地址,末尾不带 '/',当端口号为 80 时,不要添加端口号
]
```
@tab HTTPS
```py
# [!code word:https]
CORS_ALLOWED_ORIGINS: list[str] = [
'https://域名', # 前端访问地址,末尾不带 '/'
]
```
:::
## 局域网
此方式取决于前端项目是否配置了局域网服务
```py
CORS_ALLOWED_ORIGINS: list[str] = ['*']
```
---
---
url: /fastapi_best_architecture_docs/backend/reference/CRUD.md
---
# CRUD
我们在 fba 中使用 sqlalchemy-crud-plus 作为数据库操作基类,
它是一款由我们自主构建的基于 SQLAlchemy 2.0 的高级异步 CRUD SDK,它可适用于任何 FastAPI + SQLAlchemy 项目
## 函数命名
fba 遵循以下命名规范:
* 获取/查询详情: `get()`
* 通过 xxx 获取/查询详情:`get_by_xxx()`
* 获取/查询列表表达式:`get_select()`
* 获取/查询列表:`get_list()`
* 获取/查询所有:`get_all()`
* 连接查询(join):`get_with_join()`
* 关系查询(relationship):`get_with_relation()`
* 子查询:`get_children()`
* 创建:`create()`
* 更新:`update()`
* 删除:`delete()`
---
---
url: /fastapi_best_architecture_docs/backend/reference/data-permission.md
---
# 数据权限
数据权限是为了给数据添加权限而建立的,我们最常见的实现方案是仅本人数据,本部门数据...
这些就是所谓的数据权限,你可以控制不同的角色拥有不同的数据权限,从而实现用户和数据的隔离
## 常见方案
::: caution
fba 已删除此集成方式,此代码仅作为示例保留
:::
@[code python](../../code/data_perm.py)
### 弊端
我们常见的这种数据权限,在大多数情况下,也能够满足日常场景所需,但是,这种方式存在严重的弊端。由于数据权限的数据过滤是通过
SQL 语句拼接进行实现的,而这些固定权限,直接写死了数据权限的要求
例如:业务表必须包含 dept\_id 和 created\_by 字段,如果业务表没有这些字段,你就无法通过 SQL 来控制数据权限
## 内置方案
有没有一种更加灵活的方案呢,答案是,当然有,目前,我们在 fba 中实现的正是超灵活方案,但相比于常见方案来讲,配置会更加复杂
你可以直接查看代码源文件 `backend/common/security/permission.py`
,它与常规方案使用近乎相同的方式实现数据过滤,但由于其复杂性,下面,我们将通过视频进行讲解:
@[bilibili](BV13hioY1EQU)
---
---
url: /fastapi_best_architecture_docs/backend/reference/db.md
---
::: warning
fba 自 v1.10.0 开始,已将默认数据库由 MySQL 替换为 PostgreSQL
:::
fba 支持 PostgreSQL、MySQL 两种数据库,默认配置使用 PostgreSQL
## Docker 镜像
如果你未在本地安装或习惯使用 Docker 镜像,
### PostgreSQL
```shell:no-line-numbers
docker run -d \
--name fba_postgres \
--restart always \
-e POSTGRES_DB='fba' \
-e POSTGRES_PASSWORD='123456' \
-e TZ='Asia/Shanghai' \
-v fba_postgres:/var/lib/postgresql/data \
-p 5432:5432 \
postgres:16
```
### MySQL
```shell:no-line-numbers
docker run -d \
--name fba_mysql \
--restart always \
-e MYSQL_DATABASE=fba \
-e MYSQL_ROOT_PASSWORD=123456 \
-e TZ=Asia/Shanghai \
-v fba_mysql:/var/lib/mysql \
-p 3306 \
mysql:8.0.41 \
--default-authentication-plugin=mysql_native_password \
--character-set-server=utf8mb4 \
--collation-server=utf8mb4_general_ci \
--lower_case_table_names=1
```
## 环境配置
PostgreSQL 与 MySQL 在用户名、端口号等方面有所不同,如果你使用上面的命令创建了 Docker 镜像,需修改 `.env`
部分配置如下,否则,请根据实际配置进行修改
### PostgreSQL
```dotenv:no-line-numbers
# Database
DATABASE_TYPE='postgresql'
DATABASE_HOST='127.0.0.1'
DATABASE_PORT=5432
DATABASE_USER='postgres'
DATABASE_PASSWORD='123456'
```
### MySQL
```dotenv:no-line-numbers
# Database
DATABASE_TYPE='mysql'
DATABASE_HOST='127.0.0.1'
DATABASE_PORT=3306
DATABASE_USER='root'
DATABASE_PASSWORD='123456'
```
## 解耦
如果你只想保留一种数据库,参考如下:
* 删除 `with_variant` 相关代码(如果存在),仅保留数据库对应的类型
* 删除 `backend/core/conf.py` 文件中的 `DATABASE_TYPE` 及其相关的调用代码
* 删除 `.env_example` 和 `.env` 文件中的 `DATABASE_TYPE`
* 更新 `backend/templates/py/model.jinja` 文件中的 `database_type` 相关代码
* 删除 `backend/sql` 目录中不需要的文件夹
* 删除 `docker-compose.yml` 文件中不需要的容器脚本
---
---
url: /fastapi_best_architecture_docs/backend/reference/i18n.md
---
# 国际化
在现代化 web 开发中,国际化通常是前端需要做的事情,但是,在一些国际场景中,后端国际化也是必不可缺的一部分,它能为特定语言的用户反馈他们的母语提示,极大的方便了全球用户
## 语法
与前端工程常见用法基本一致,只需使用 `t()` 函数 + 链式文本即可,例如:
* `t('response.success')`
获取语言包中的 response 下的 success 字段值
* `t('error.captcha.expired‘)`
获取语言包中的 error 下的 captcha 下的 expired 字段值
## 默认语言
可以在 [配置文件](./conf.md) 中设置默认语言
## 动态切换
fba 将自动获取请求头中的 `Accept-Language` 参数,并应用第一个参数值为当前语言,如果此参数不存在,则应用默认语言
```mermaid
---
title: t 函数处理流程
---
flowchart TD
A[解析链式文本] --> B{获取语言包}
B -- 存在 --> C[匹配链]
B -- 不存在 --> D[返回错误提示]
C -- 成功 --> E[返回语言文本]
C -- 失败 --> F[返回链式文本]
```
## 语言包
语言包位于 `backend/app/locale` 目录下
### 命名
语言包文件的命名通常遵循国家/地区代码,例如,`en-US` 表示英语,`zh-CN` 表示简体中文
### 格式
语言包目前支持两种格式:
* json
* yaml / yml
---
---
url: /fastapi_best_architecture_docs/backend/reference/jwt.md
---
我们编写了 JWT 授权中间件,使其可以在每次请求发起时,能够实现自动授权,并且还使用 Redis 和 Rust
库对用户信息进行缓存和解析,使其性能影响尽可能降到最低
## 接口鉴权
在文件 `backend/common/security/jwt.py` 中,包含以下代码
```python
# JWT dependency injection
DependsJwtAuth = Depends(HTTPBearer())
```
我们通过在接口函数中添加此依赖实现 JWT 快速校验,它可以帮助我们检查请求头中是否包含 Bearer Token,使用方式参考如下:
```python{1}
@router.get('/hello', summary='你好', dependencies=[DependsJwtAuth])
async def hello():
...
```
## Token
内置 token 授权方式遵循 [rfc6750](https://datatracker.ietf.org/doc/html/rfc6750)
## Swagger 登录
这是一种快捷的授权方式,仅用于调试目的,在服务启动后,进入 Swagger 文档,可通过此调试接口快速获取 token(无需验证码)
## 验证码登录
你可以通过此方式获取 token,在大多数情况下,这更适用于配合前端实现登录授权
我们在 fba 中使用 [fast\_captcha](https://github.com/wu-clan/fast-captcha) 生成 base64 验证码,然后通过接口进行数据返回;您可以通过在线
base64 转图片或配合前端项目将其转为图片进行预览
### 授权流程
```sequence 验证码登录逻辑
actor 客户端
客户端 ->> 路由: GET
/api/v1/auth/captcha
路由 ->> 频率限制器: 校验请求频率
频率限制器 -->> 路由: 允许
路由 ->> fast_captcha: 生成随机验证码
fast_captcha ->> Redis: 缓存验证码
客户端 ->> 路由: POST
/api/v1/auth/login
路由 ->> 频率限制器: 校验请求频率
频率限制器 -->> 路由: 允许
路由 ->> 用户名: 校验用户名是否在系统中存在
用户名 -->> 路由: 通过
路由 ->> 验证码: 校验验证码(缓存和图片内容)
验证码 -->> 路由: 通过
路由 ->> Token: 生成 Token
Token -->> 客户端: 成功
```
---
---
url: /fastapi_best_architecture_docs/backend/reference/limit.md
---
在现代 Web 开发中,API 限流(Rate
Limiting)是保护后端服务、防止资源滥用、保证服务稳定性的重要机制,我们有一个关于路由器的历史讨论,如果你感兴趣,可以查看:[#70](https://github.com/fastapi-practices/fastapi_best_architecture/discussions/70)
## 处理流程
以下是 RateLimiter 处理一次请求的完整流程:
```mermaid
graph TD
A[请求进入路由依赖] --> B[初始化 Bucket 和 Limiter]
B --> C[获取 Identifier]
C --> D[异步尝试获取]
D -->|获取成功| E[放行请求,继续业务处理]
D -->|获取失败| F[计算 Retry-After]
F --> G[执行 Callback
(默认抛出 429 异常)]
```
## 使用方法
RateLimiter 设计为 FastAPI 的依赖项,直接在路由中使用 `Depends` 注入
### 单规则限流
```python
# 每分钟最多 60 次
@app.get(
"/api/example",
dependencies=[Depends(RateLimiter(Rate(5, Duration.MINUTE)))]
)
async def example():
return {"message": "success"}
```
### 多规则复合限流
```python
# 每秒 10 次 + 每分钟 100 次
@app.post(
"/api/heavy",
dependencies=[
Depends(
RateLimiter(
Rate(10, Duration.SECOND),
Rate(100, Duration.MINUTE),
)
)
]
)
async def heavy_endpoint():
return {"status": "ok"}
```
### 自定义 Identifier
```python
async def user_identifier(request: Request) -> str:
return f"user:{request.user.id}"
@app.get(
"/api/user-data",
dependencies=[
Depends(
RateLimiter(
Rate(50, Duration.MINUTE),
identifier=user_identifier,
)
)
]
)
async def user_data():
return {"data": "protected"}
```
---
---
url: /fastapi_best_architecture_docs/backend/reference/model.md
---
通用模型位于 `backend/common/model.py` 文件中
## 主键
我们未提供自动主键模式,而是必须通过手动定义的方式进行主键声明
### 自增 ID
```python
# 通用 Mapped 类型主键, 需手动添加,参考以下使用方式
# MappedBase -> id: Mapped[id_key]
# DataClassBase && Base -> id: Mapped[id_key] = mapped_column(init=False)
id_key = Annotated[
int,
mapped_column(
BigInteger,
primary_key=True,
unique=True,
index=True,
autoincrement=True,
sort_order=-999,
comment='主键 ID',
),
]
```
### 雪花 ID
[**切换主键**](pk.md){.read-more}
## Mixin 类
[Mixin](https://en.wikipedia.org/wiki/Mixin) 是一种面向对象编程概念, 使结构变得更加清晰
### 操作人
用于集成操作人信息到数据库表
::: warning
在 fba 中,并没有默认集成操作人员信息到各个数据库表,但是我们提供了非常简易的集成方式
[**操作人博客**](../../blog/operator.md){.read-more}
:::
### 日期时间
用于集成日期时间到数据库表,已集成在 [Base](#base-基类) 基类中
```python
class DateTimeMixin(MappedAsDataclass):
"""日期时间 Mixin 数据类"""
created_time: Mapped[datetime] = mapped_column(
TimeZone, init=False, default_factory=timezone.now, sort_order=999, comment='创建时间'
)
updated_time: Mapped[datetime | None] = mapped_column(
TimeZone, init=False, onupdate=timezone.now, sort_order=999, comment='更新时间'
)
```
## 数据类基类
声明性数据类基类,它将带有数据类集成,允许使用更高级配置,==但未集成日期时间=={.note}
了解 [MappedAsDataclass](https://docs.sqlalchemy.org/en/20/orm/dataclasses.html#orm-declarative-native-dataclasses)
```python
class DataClassBase(MappedAsDataclass, MappedBase):
__abstract__ = True
```
## Base 基类
声明性数据类基类,带有数据类和日期时间集成
```python
class Base(DataClassBase, DateTimeMixin):
__abstract__ = True
```
## 字符串类型
对于长文本,fba 提供了内置的 PostgreSQL 和 MySQL 兼容类型 `UniversalText`
对于常见文本,fba 通常使用以下长度单位:`32`、`64`、`128`、`256`、`512`
---
---
url: /fastapi_best_architecture_docs/backend/reference/oauth2.md
---
# OAuth 2.0
我们在 fba 中使用 [fastapi-oauth20](https://github.com/fastapi-practices/fastapi-oauth20) 集成 OAuth 2.0,您可以在
`backend/plugin/oauth2` 目录中查看我们的官方实现示例
::: note
此授权方式适用于第三方平台认证登录,第三方授权成功后,将依据第三方平台信息自动创建本地用户并自动授权登录,用户只需同意第三方授权即可
但是,想要使用此方式进行授权,你需要先了解 OAuth 2.0 相关知识,并遵循第三方平台认证要求,获取第三方平台授权密钥,最终,手动编码完成集成
:::
---
---
url: /fastapi_best_architecture_docs/backend/reference/pagination.md
---
# 分页
后期将发生改变,需等待 PR
合并:[Allow to have multiple Query parameter models](https://github.com/fastapi/fastapi/pull/12944#pullrequestreview-2588580175)
---
---
url: /fastapi_best_architecture_docs/backend/reference/pk.md
---
# 主键
我们在 fba 中为数据库主键添加了两种选择,分别为传统模式(自增 ID)和雪花算法(雪花 ID),==我们在全局范围内使用 `自增 ID`
作为主键的默认声明方式=={.note}
在切换主键声明方式之前,让我们先来简单了解一下它们的特性,再决定是否需要切换
## 自增 ID
### 优点
* 简单易用
* 数据库原生支持
* 生成顺序递增
* 查询效率高
* 占用空间小
### 局限性
* 在分布式系统中可能出现 ID 冲突,扩展性较差
* ID 生成依赖数据库,性能瓶颈风险较高
* ID 可预测,可能暴露业务数据量或存在安全隐患
## 雪花 ID
### 优点
* 分布式环境友好
* ID 全局唯一且无需依赖中央数据库
* 包含时间戳,生成 ID 天然有序,便于排序和查询
### 局限性
* 实现复杂,需额外维护生成器
* 可能因时间回拨(如服务器时钟同步问题)导致无法新增数据
* ID 长度较长,存储和传输成本略高
## 适用场景
### 自增 ID
单机或中小规模应用,业务简单且对 ID 可预测性无敏感
### 雪花 ID
分布式系统、微服务架构,或需要高并发、跨地域生成唯一 ID
## 切换选择
::: warning
在切换选择之前,请确认以下事项
* 未启动过项目
* 未执行过 alembic 迁移
* `backend/core/conf.py` 文件中的 `DATABASE_SCHEMA` 配置符合预期
如果存在以上操作,在切换选择前,必须删除所有数据库表
:::
::: caution
不要随意切换选择!自增 ID 会创建数据库物理绑定,随意切换将导致致命问题!!!
:::
### 自增 ID
无需切换,这是 fba 内的全局默认声明方式
### 雪花 ID
1. 务必仔细查看本章节警告内容,确保数据库环境整洁
2. 更新 `backend/core/conf.py` 中的 `DATABASE_PK_MODE` 配置为 `snowflake`
3. 阅读 [注意事项](#注意事项)
::: caution Windows 平台警告
如果您正在 Windows 平台中使用 mysql >= 8.0,还需要更新 `backend/database/db.py` 文件内的 `mysql+asyncmy` 为
`mysql+aiomysql`,否则,您将无法在本地正常新增数据。相关
issue:[asyncmy/issues/35](https://github.com/long2ice/asyncmy/issues/35)
:::
## 注意事项
* 使用雪花 ID 时,需确保时钟同步(如通过 NTP)和节点 ID 的唯一性分配
* 传统自增 ID 在数据迁移或合并时需特别注意冲突问题
* \==前端渲染长整数偏移=={.danger}
当后端 api 返回长整数时,返回结果是没有问题的,但是通过前端渲染数据后,可能导致长整数渲染错误。
通过浏览器控制台可以发现,前端渲染后的数据 id 与返回数据不一致,最佳解决方法是:后端将长整数序列化为字符串之后再返回;以下提供两种方案,
仅供参考:
::: tabs
@tab schemaBase
```python
@field_serializer('id', check_fields=False)
def serialize_id(self, value: int) -> str | int:
if self.model_config.get('from_attributes'):
return str(value)
return value
```
@tab GetXxxDetail / GetXxxTree
```python
@field_serializer('id')
def serialize_id(self, value) -> str:
return str(value)
```
---
---
url: /fastapi_best_architecture_docs/backend/reference/RBAC.md
---
# RBAC
我们通过自定义依赖组件,实现了 RBAC 的轻松集成,它可以通过 FastAPI Depends 轻松集成
::: caution
自 v1.2.0 开始,默认 RBAC 已更换为【[角色菜单](#角色菜单)】,【[Casbin-RBAC](#casbin)】将作为外置插件进行分发
:::
## 角色菜单
要想实现此 RBAC 鉴权,需要进行以下配置
::: steps
1. 添加接口依赖
只有在接口中添加以下依赖时,才能自动调用此鉴权方式
```py{5-6}
@router.post(
'',
summary='xxx',
dependencies=[
Depends(RequestPermission('sys:api:add')), # 通常为 xxx:xxx:xxx
DependsRBAC,
],
)
```
2. 在系统菜单中添加权限标识
我们在接口依赖中可以看到 `sys:api:add` 之类的值,这些值正是对应着菜单中的权限标识字段,只有它们完全一致,并且用户拥有对应的菜单时,才可以获得相应的操作权限
:::
## Casbin
此方案是 Go 语言中比较流行的解决方案,它非常灵活,可以通过模型定义多种控制规则
要想实现此 RBAC 鉴权,请先 [获取插件](../../marketplace.md),然后执行以下操作
::: steps
1. 安装插件
2. 启用鉴权
修改 `backend/core/conf.py` 文件中的 `RBAC_ROLE_MENU_MODE` 为 `False`
:::
## 解耦
在实际项目开发中,不可能同时存在多种 RBAC 解决方案,您可以通过以下方式删除【角色菜单】集成
* 删除 `backend/common/security/permission.py` 文件中的 `RequestPermission` 类及所有类调用
* 删除 `backend/core/conf.py` 文件中的 `RBAC_ROLE_MENU_MODE` 和 `RBAC_ROLE_MENU_EXCLUDE`
* 删除 `backend/common/security/rbac.py` 文件中 `rbac_verify` 方法里面的 `if settings.RBAC_ROLE_MENU_MODE:`
条件及相关代码
* 删除菜单 `perms` 列及其相关的 schema 字段和 SQL 脚本
* 删除菜单 `type` 列中的按钮类型及其按钮类型相关的代码逻辑和 SQL 脚本
---
---
url: /fastapi_best_architecture_docs/backend/reference/response.md
---
# 接口响应
我们为 fba 开发了十分灵活且健全的接口响应系统,它同时适用于任何 FastAPI 应用
## 统一返回模型
在常规 web 应用开发中,通常情况下,响应结构总是统一的,但在 FastAPI 的官方教程中,并没有提示我们该如何这样做,其实,这很简单,
只需我们提供一个统一的 pydantic 模型
```python
class ResponseModel(BaseModel):
code: int = CustomResponseCode.HTTP_200.code
msg: str = CustomResponseCode.HTTP_200.msg
data: Any | None = None
```
以下是使用此模型进行返回的示例(遵循 FastAPI 官方教程),`response_model` 参数和 `->` 类型选择其中一种方式即可,FastAPI
会在内部自动解析并获取最终响应结构
`response_model` 参数:
```python{1,3}
@router.get('/test', response_model=ResponseModel)
def test():
return ResponseModel(data={'test': 'test'})
```
`->` 类型:
```python{2,3}
@router.get('/test')
def test() -> ResponseModel:
return ResponseModel(data={'test': 'test'})
```
## Schema 模式
上面我们已经讲解了统一返回模型,但是,FastAPI 中的优势之一还包括完全自动的 OpenAPI 和文档,如果我们全局使用
ResponseModel 做为统一响应模型,你会在 Swagger 文档得到(如图所示)
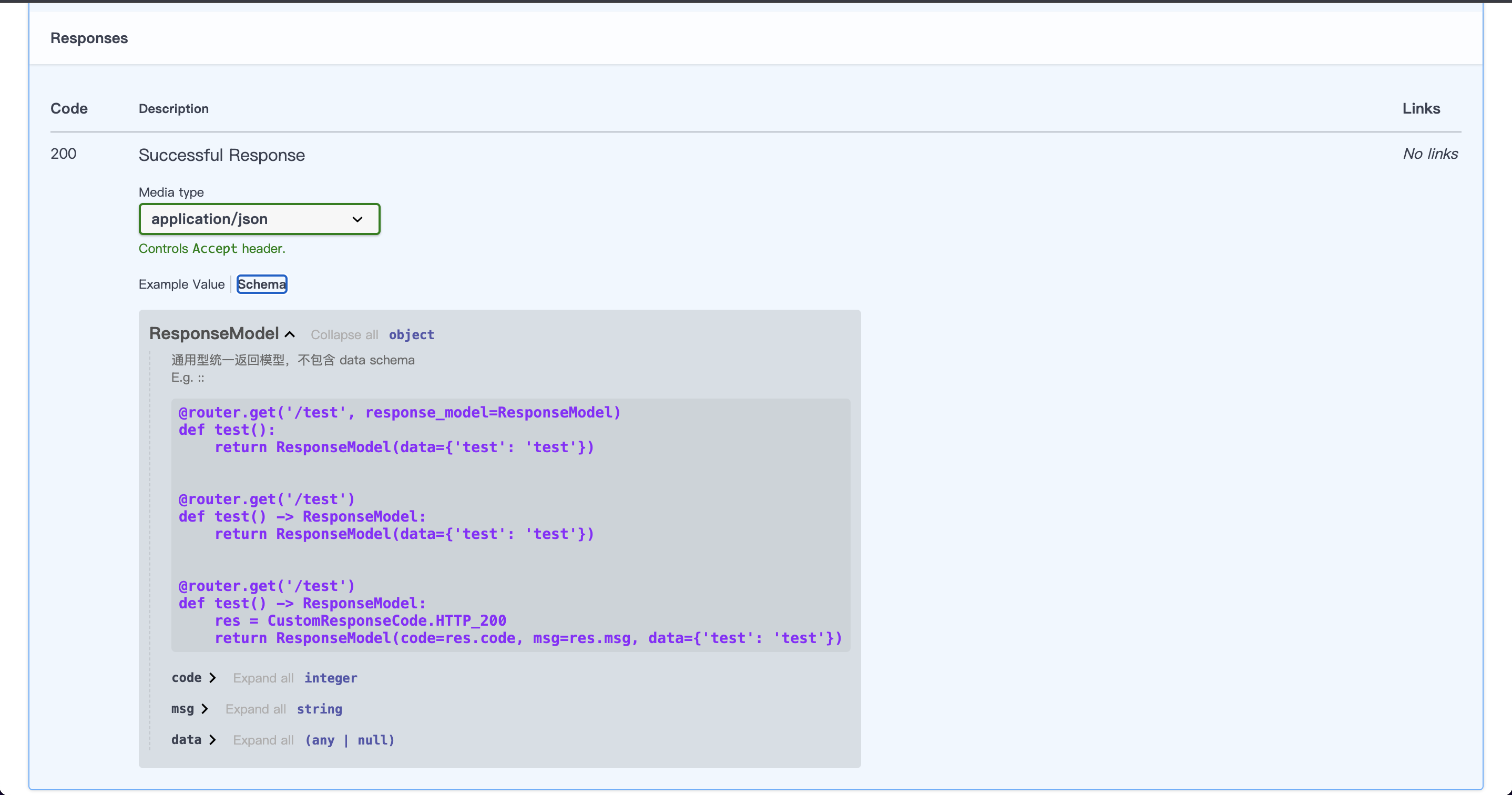
显然,我们无法获取响应中的 data 数据结构。此时前端同事找到你,你会告诉他们,你请求一下不就行了?(没毛病,但显然不太友好),下面是我们创建的用于
Schema 模式的统一返回模型
```python
class ResponseSchemaModel(ResponseModel, Generic[SchemaT]):
data: SchemaT
```
以下是使用此模型进行返回的示例(遵循 FastAPI 官方教程),它的用法与 ResponseModel 基本相似
`response_model` 参数:
```python{1,3}
@router.get('/test', response_model=ResponseSchemaModel[GetApiDetail])
def test():
return ResponseSchemaModel[GetApiDetail](data=GetApiDetail(...))
```
`->` 类型:
```python{2,3}
@router.get('/test')
def test() -> ResponseSchemaModel[GetApiDetail]:
return ResponseSchemaModel[GetApiDetail](data=GetApiDetail(...))
```
此时我们再来看一眼 Swagger 文档
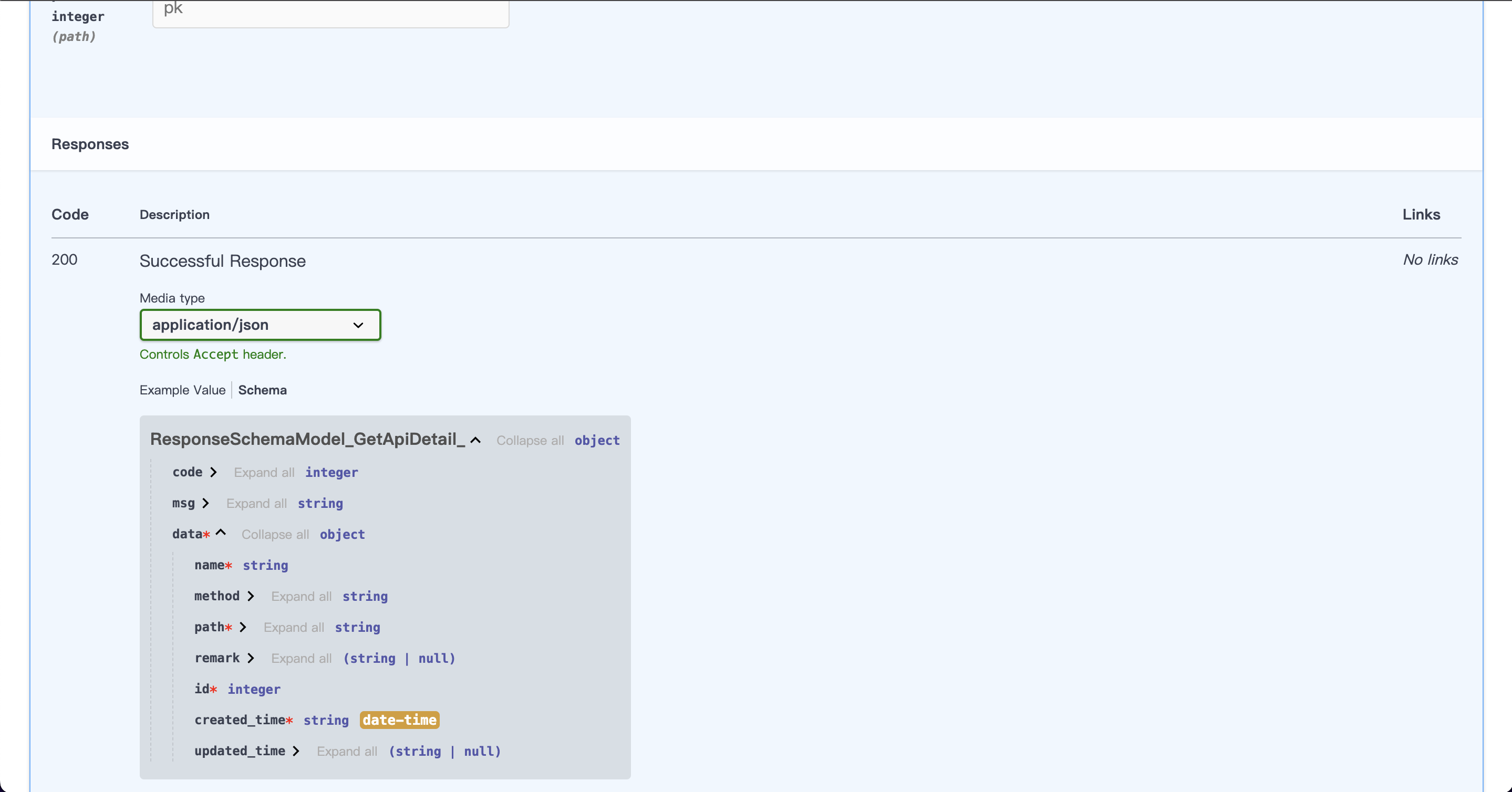
我们可以看到,响应 Schema 中的 data 已经包含我们的响应体结构了,响应体结构正是解析的 `[]` 中的 Schema 模型,它们是对应的,如果返回的数据结构与
Schema 不一致,将引发解析错误
我们建议将这种方式仅用于查询接口,如果你不需要这种文档,你完全可以不使用它,而是使用更加开放的统一响应模型
ResponseModel
## 统一返回方法
`response_base` 是我们做的全局响应实例,它大大简化了响应返回方式,用法如下:
```python{2-3,7-8}
@router.get('/test')
def test() -> ResponseModel:
return response_base.success(data={'test': 'test'})
@router.get('/test')
def test() -> ResponseSchemaModel[GetApiDetail]:
return response_base.success(data=GetApiDetail(...))
```
此实例包含三个返回方法:`success()`、`fail()`、`fast_sucess()`
::: warning
它们都是同步方法,而不是异步。因为这些返回方法并不涉及 io 操作,所以,定义为异步,不但没有性能提升,反而增加了异步协程的开销
:::
::: tabs
@tab `success()`
此方法通常作为默认响应方法使用,默认返回信息如下
```json:no-line-numbers
{
"code": 200,
"msg": "请求成功",
"data": null
}
```
@tab `fail()`
此方法通常在接口响应信息为失败时使用,默认返回信息如下
```json:no-line-numbers
{
"code": 400,
"msg": "请求错误",
"data": null
}
```
@tab `fast_success()`
此方法通常仅用于接口返回大型 json 时,可为 json 解析性能带来质的提升,默认返回信息如下
```json:no-line-numbers
{
"code": 200,
"msg": "请求成功",
"data": null
}
```
:::
## 响应状态码
在文件 `backend/common/response/response_code.py` 中内置了多种定义响应状态码的方式,我们可以根据 `CustomResponseCode` 和
`CustomResponse` 定义自己需要的的响应状态码,因为在实际项目中,响应状态码并没有统一的标准
当我们定义好自定义响应状态码之后,可以像下面这样使用
```python{3-4}
@router.get('/test')
def test() -> ResponseModel:
res = CustomResponse(code=0, msg='成功')
return ResponseModel(res=res, data={'test': 'test'})
```
## 驼峰返回
我们默认使用 python 下划线命名法进行数据返回,但是,在实际工作中,前端目前大多使用小驼峰命名法,所以,我们就需要对此进行一些修改来适配前端工程,在文件
`backend/common/schema.py` 中,我们有一个 `SchemaBase` 类,它是我们的全局 Schema 基础类,修改如下:
```python
class SchemaBase(BaseModel):
model_config = ConfigDict(
populate_by_name=True, # [!code ++] 允许通过原始字段名或别名进行赋值
alias_generator=to_camel, # [!code ++] 自动将字段名转换为小驼峰
use_enum_values=True,
json_encoders={datetime: lambda x: x.strftime(settings.DATETIME_FORMAT)},
)
```
其中,`to_camel` 方法引入自
pydantic,详情:[pydantic.alias\_generators](https://docs.pydantic.dev/latest/api/config/#pydantic.alias_generators)
完成以上修改后,Schema 模式和返回数据将自动转为小驼峰命名
## 国际化
[**国际化**](./i18n.md){.read-more}
---
---
url: /fastapi_best_architecture_docs/backend/reference/router.md
---
# 路由
fba 中的路由遵循 Restful API 规范
## 路由结构
我们有一个关于路由器的历史讨论,如果你感兴趣,可以查看:[#4](https://github.com/fastapi-practices/fastapi_best_architecture/discussions/4)
当前路由结构如下所示:
::: file-tree
* backend 后端
* app 应用
* xxx 自定义应用
* api 接口
* v1
* xxx 子包
* **init**.py 在此文件内注册子包内 xxx.py 文件中的路由
* xxx.py
* ...
* **init**.py
* router.py 在此文件内注册所有子包 **init**.py 文件中的路由
* xxx 自定义应用
* api 接口
* v1
* **init**.py 不做任何操作
* xxx.py
* ...
* **init**.py
* router.py 在此文件内注册所有 xxx.py 文件中的路由
* **init**.py
* router.py 在此文件内注册所有 app 目录下 router.py 文件中的路由
:::
::: warning
我们统一命名了所有接口路由参数为 router,这很有助于我们编写接口,但是,不可忽略的是,在注册路由时,一定要注意我们的导入方式
在 fba 中,我们可以查看所有路由的导入,它们看起来像 `from backend.app.admin.api.v1.sys.api import router as api_router`
,我们这里务必导入文件内的路由参数 `router`,为了避免参数名称冲突,我们可以使用 `as` 为路由参数起一个别名
:::
---
---
url: /fastapi_best_architecture_docs/backend/reference/schema.md
---
# schema
在 fba 中,我们为 Schema 进行了大量量身定制,详情请查看:`backend\common\schema.py`
## 类命名
遵循以下命名规范:
* 基础 schema: `XxxSchemaBase(SchemaBase)`
* 接口入参:`XxxParam()`
* 新增入参:`CreateXxxParam()`
* 更新入参:`UpdateXxxParam()`
* 批量删除入参:`DeleteXxxParam()`
* 查询详情:`GetXxxDetail()`
* 查询详情(join):`GetXxxWithJoinDetail()`
* 查询详情(relationship):`GetXxxWithRelationDetail()`
* 查询树:`GetXxxTree()`
## Field 定义
* 不建议将必填字段默认值设置为 `...`,参考:[必填字段](https://docs.pydantic.dev/latest/concepts/models/#required-fields)
* 建议为所有字段添加 `description` 参数,这对于 API 文档来说非常有用
## 驼峰返回
[**接口响应**](response.md#驼峰返回){.read-more}
---
---
url: /fastapi_best_architecture_docs/backend/reference/socketio.md
---
# Socketio
## 为什么不用 ws
WebSocket 已被集成到 fastapi 中,并且可以直接使用,为什么还要 socketio?原因有很多,可以简单概括为 socektio 功能性和稳定性更高,如果使用
ws,很多东西可能还要手搓封装,但 socektio 把这些东西基本都写好了,所以,何乐而不为呢
## 什么是 socketio?
socketio 是一种传输协议,可以在客户端和服务器之间实现基于事件的实时双向通信
没有 socketio 时:
你的 leader 在出差,给你任命了一项非常着急的任务,这项任务就等同于事件,但你并不能很快的完成此任务,可是你的 leader
过一会儿就会问你怎么样了(轮询),你很烦,不想理他(延迟反应)
使用 socketio 时:
你的 leader 就坐在你的旁边,你的工作效率飞升,马上就完成了任务,并且直接口头传达了完成,他立马就听见了(实时)
## 集成
在 fba 中,你可以在 `backend/common/socketio/` 目录下查阅本地 socketio 实现,其中包含两个文件
`actions.py`:此文件主要用于定义一些全局事件,方便我们对事件进行统一管理
`server.py`:此文件是在 fba 中的服务端标准实现,其中包含 socketio 授权连接
但这些并不是主要集成代码,我们可以进入 `backend/core/register.py` 文件,找到以下方法
```python
def register_socket_app(app: FastAPI):
"""
socket 应用
:param app:
:return:
"""
from backend.common.socketio.server import sio
socket_app = socketio.ASGIApp(
socketio_server=sio,
other_asgi_app=app,
# 切勿删除此配置:https://github.com/pyropy/fastapi-socketio/issues/51
socketio_path='/ws/socket.io',
)
app.mount('/ws', socket_app)
```
我们通过 `python-socketio` ASGI 应用定义方式,分别将 socketio 和 fastapi 应用作为参数填入,此时你已创建了一个 socket
应用,然后我们通过 fastapi 内置的挂载功能,将 socket 应用挂载到 fastapi 应用中,至此,你已完成 fastapi 集成 socketio
---
---
url: /fastapi_best_architecture_docs/backend/reference/sso.md
---
# SSO
SSO(单点登录,Single Sign-On)是一种身份验证机制,允许用户只需登录一次即可访问多个相关系统或应用,无需重复输入凭据
**优点:**
* 提升用户体验,减少登录次数
* 简化企业身份管理,统一权限控制
* 增强安全性,支持多因素认证,降低密码泄露风险
**适用场景**:企业内部系统、云服务、跨平台应用等
## 集成
我们将通过 [casdoor](https://casdoor.org/) 实现 SSO 集成,并将其作为 [SSO 插件](../../marketplace.md) 发布
有关 SSO 的实现细节和更多用法请访问 casdoor 官方文档
---
---
url: /fastapi_best_architecture_docs/backend/reference/timezone.md
---
# 时区
我们为全局精心设计了统一时区,现在,这是一件非常轻松的工作,只需修改 `backend/core/conf.py` 中的时区配置即可改变全局时区
::: caution
时区一旦确定,强烈建议不要后期修改,否则可能造成持久化数据时间信息紊乱!
:::
## 架构应用
无论在架构何处调用时间模块,我们都应使用 `backend/utils/timezone.py` 中提供的现有方法,而不是直接调用 datetime 相关模块
## 数据库
在数据库中处理时区是一件令人头疼的事,常见的方式有以下 3 种:
* 全部存读为 UTC,前端转化(利于国际化管理)
* 全部存读当前时区时间,根据前端传入的时区进行转换(利于本地化管理)
* 全部存储为数值时间戳,前端转化(极其不易管理,但易操作)
让我们来看一个经典案例:
::: chat title="群聊"
{:2025-08-26 12:44:00}
{王}
请教大佬,为啥我查询的时间用的不同的时区和时间戳,返回的数据却是一样的?

数据库用的是 mysql,原则上这两个 datetime 的时间戳是不一样的,但是查出来的数据是一样的结果;
{王}
我直接写 sql 查询,这个两个是符合预期结果的,第一个有数据,第二个查不到;
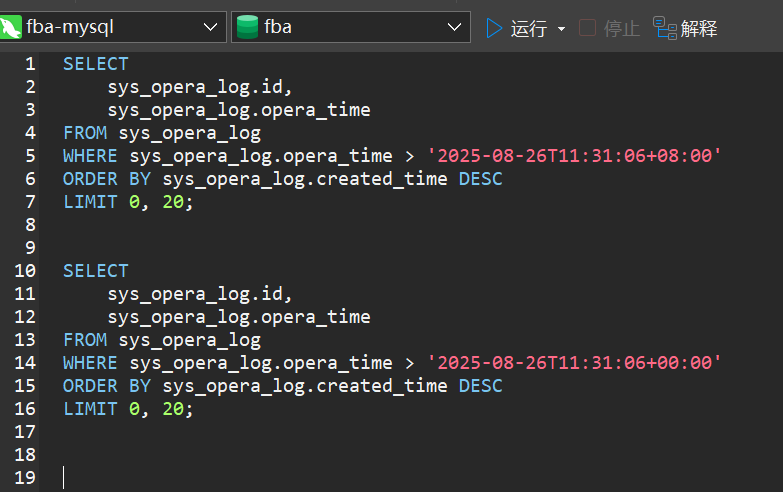
这个切换到pg数据库后查询符合预期结果的;
{.}
**timezone**: not used by the MySQL dialect.
sqlalchemy 和所有 python mysql 驱动默认都不处理 mysql 时区信息,通常是直接丢弃,即便使用 TIMESTAMP 类型
{.}
更具体的:[sqlalchemy/1985](https://github.com/sqlalchemy/sqlalchemy/issues/1985)
:::
为此,我们使用了第 2 种解决方案,并创建了自定义 TimeZone 类型
```python
class TimeZone(TypeDecorator[datetime]):
"""PostgreSQL、MySQL 兼容性时区感知类型"""
impl = DateTime(timezone=True)
cache_ok = True
@property
def python_type(self) -> type[datetime]:
return datetime
def process_bind_param(self, value: datetime | None, dialect) -> datetime | None: # noqa: ANN001
if value is not None and value.utcoffset() != timezone.now().utcoffset():
# TODO 处理夏令时偏移
value = timezone.from_datetime(value)
return value
def process_result_value(self, value: datetime | None, dialect) -> datetime | None: # noqa: ANN001
if value is not None and value.tzinfo is None:
value = value.replace(tzinfo=timezone.tz_info)
return value
```
---
---
url: /fastapi_best_architecture_docs/backend/reference/transaction.md
---
默认情况下,如果将数据库引擎参数 `echo` 设置为 True,你将会看到事务总是被开启,即便那是一个查询语句。但这并不是因为我们错误的使用了
SQLAlchemy,你可以查看 [#6921](https://github.com/sqlalchemy/sqlalchemy/discussions/6921)、[#12782](https://github.com/sqlalchemy/sqlalchemy/discussions/12782)
了解详情
::: details 简要总结
任何遵循 [PEP-429](https://peps.python.org/pep-0249) 进行设计的 Python 数据库连接器或 ORM,都将默认开启事务
在 SQLAlchemy 中,你可以选择不使用它自身的事务模式,但这需要将数据库本身的事务隔离级别设置为 `AUTOCOMMIT`
,详情请查看: [了解 DBAPI 级别的 Autocommit 隔离级别](https://docs.sqlalchemy.org.cn/en/20/core/connections.html#understanding-the-dbapi-level-autocommit-isolation-level)
:::
## CurrentSession
这是一种类似于官方文档的使用方法,但这种方法并没有真正开启事务,它通常仅用于查询操作
```python
async def get_db() -> AsyncGenerator[AsyncSession, None]:
"""获取数据库会话"""
async with async_db_session() as session:
yield session
# Session Annotated
CurrentSession = Annotated[AsyncSession, Depends(get_db)]
```
这种方法通常直接应用于接口函数,在 session 应用方面,它被认为是线程安全的
```python
@router.get('')
async def get_pagination_apis(db: CurrentSession) -> ResponseModel:
...
```
## CurrentSessionTransaction
与 `CurrentSession` 不同,此方法将直接自动开启事务,你可以将它用于增删改操作
```python
async def get_db_transaction() -> AsyncGenerator[AsyncSession, None]:
"""获取带有事务的数据库会话"""
async with async_db_session.begin() as session:
yield session
# Session Annotated
CurrentSessionTransaction = Annotated[AsyncSession, Depends(get_db_transaction)]
```
使用方法与 `CurrentSession` 相同
```python
@router.post('')
async def get_pagination_apis(db: CurrentSession) -> ResponseModel:
...
```
## `begin()`
这种方式由 SQLAlchemy 官方实现,在线程安全方面,由于在同一个函数中,可能存在多次调用,所以没有 `CurrentSession` 和
`CurrentSessionTransaction` 更加严谨,但此方式可以在任意地方使用
```python{2}
async def create(*, obj: CreateIns) -> None:
async with async_db_session.begin() as db:
await xxx_dao.create(db, obj)
```
---
---
url: /fastapi_best_architecture_docs/backend/summary/intro.md
---
# 简介
基于 FastAPI 构建的企业级后端架构解决方案
## 伪三层架构
mvc 架构作为常规设计模式,在 python web 中很常见,但是三层架构更令人着迷
在 python web 开发中,三层架构的概念并没有通用标准,所以这里我们称之为伪三层架构
!但请注意 !
我们并没有传统的多 app (微服务)目录结构(django、springBoot...),而是[自以为是的目录结构](#项目结构)
如果您不喜欢这种模式,可以对其进行任意改造!
| 模块 | java | fastapi\_best\_architecture |
|------|----------------|---------------------------|
| 视图 | controller | api |
| 数据传输 | dto | schema |
| 业务逻辑 | service + impl | service |
| 数据访问 | dao / mapper | crud |
| 模型 | entity | model |
## 特性
* \[x] 全异步设计(async/await + asgiref)
* \[x] 遵循 RESTful API 设计规范
* \[x] SQLAlchemy 2.0 现代语法
* \[x] Pydantic v2 全栈数据验证
* \[x] 角色菜单 RBAC 权限控制
* \[x] 原生 Celery 异步任务支持
* \[x] 自研高性能 JWT 认证中间件
* \[x] 全局自定义时区处理
* \[x] 一键 Docker / Docker-Compose 部署
* \[x] 集成 Pytest 单元测试
* \[x] Grafana 全链路可观测性
## 内置功能
* \[x] 用户管理:灵活分配角色与权限
* \[x] 部门管理:轻松构建组织架构
* \[x] 菜单管理:精准到按钮级的权限配置
* \[x] 角色管理:一站式角色权限分配
* \[x] 字典管理:全局参数统一维护
* \[x] 参数管理:运行时动态配置系统参数
* \[x] 通知公告:快速发布系统消息
* \[x] 令牌管理:实时在线监测 + 强制下线
* \[x] 多端登录:一键切换多终端模式
* \[x] 自研 OAuth 2.0:开箱即用授权登录
* \[x] 插件系统:零耦合扩展,随意拼装
* \[x] 定时任务:灵活调度异步任务
* \[x] 代码生成:一键预览、写入、下载
* \[x] 操作日志:完整记录正常/异常操作
* \[x] 登录日志:详尽追踪登录行为
* \[x] 缓存监控:实时查看缓存统计
* \[x] 服务监控:服务器硬件与状态一目了然
* \[x] 接口文档:自动生成交互式 Swagger 文档
## 项目结构
::: file-tree
* backend 后端
* alembic/ 数据库迁移
* app 应用
* admin/ 系统后台
* api/ 接口
* crud/ CRUD
* model 模型
* **init**.py 必须在此文件内导入所有模型类
* …
* schema/ 数据传输
* service/ 服务
* tests/ 单元测试
* task/ 任务
* …
* common/ 公共资源
* core/ 核心配置
* database/ 数据库连接
* langs/ 国际化语言包
* log/ 日志
* middleware/ 中间件
* plugin 插件
* code\_generator/ 代码生成
* …
* scripts/ 脚本
* sql/ SQL 文件
* static/ 静态文件
* templates/ 模版文件
* utils/ 工具包
* deploy/ 服务器部署
* …
:::
## 贡献者
## 许可证
本项目由 [MIT](https://github.com/fastapi-practices/fastapi_best_architecture/blob/master/LICENSE) 许可证的条款进行许可
[](https://starchart.cc/fastapi-practices/fastapi_best_architecture)
## 特别鸣谢
* [downdawn](https://github.com/downdawn) 积极推动创建此项目
* [无名](https://github.com/lvright) 精心设计的 LOGO(包含了 fba 三个字母抽象结合,形成了一个类似从地面扩散投影上来的闪电)
* [vuepress-theme-plume](https://github.com/pengzhanbo/vuepress-theme-plume) 为官网文档提供驱动支持
* FastAPI、SQLAlchemy、Pydantic 等开源先行者
* 所有赞助商们(包含所有渠道)的大力支持
* 此项目的所有贡献者、参与者和使用者
---
---
url: /fastapi_best_architecture_docs/backend/summary/quick-start.md
---
# 快速开始
::: caution
fba 仅适用于资深 Python 后端开发人员,如果您是小白用户,我们建议您打好基础再来学习
:::
## 本地开发
:::: steps
1. 准备本地环境
* Python 3.10+
* [安装 uv](https://docs.astral.sh/uv/getting-started/installation/)(推荐最新稳定版)
* PostgreSQL 16.0 + 或 MySQL 8.0+
[使用**雪花主键 ID**](../reference/pk.md){.read-more}
[使用 **MySQL**](../reference/db.md){.read-more}
2. 准备源码
::: tabs
@tab 拉取源代码
```shell:no-line-numbers
git clone https://github.com/fastapi-practices/fastapi_best_architecture.git
```
@tab 创建模板仓库
此项目支持创建模板仓库,意味着,你可以直接创建一个非 fork 的个人仓库,如图所示,进入此项目
GitHub 首页,使用 `use this template` 按钮创建
创建完成之后,使用 `git clone` 命令拉取你自己的仓库即可
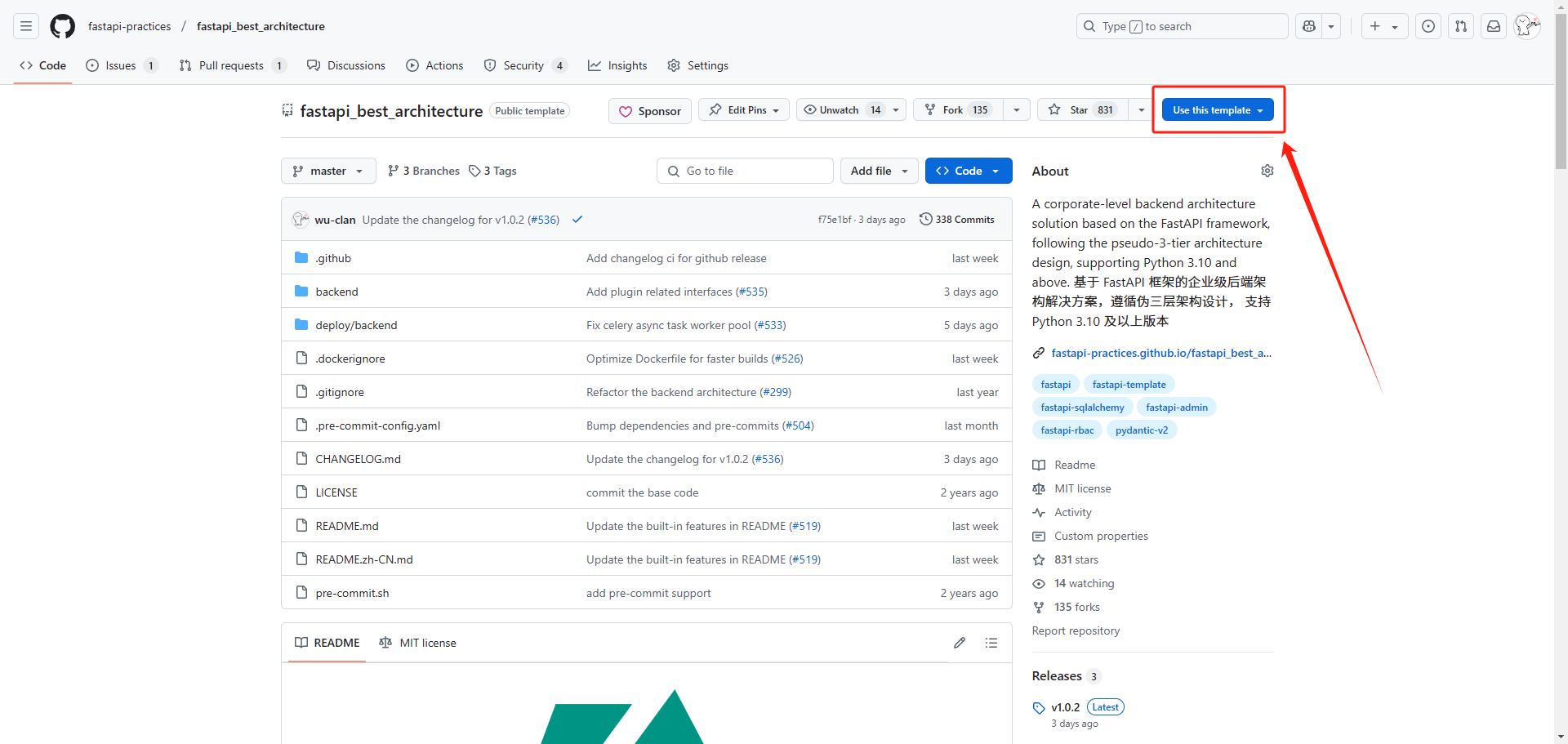
:::
3. 启动 PostgreSQL/MySQL、Redis
4. 初始化
::: tabs
@tab 自动
在 `根目录` 打开终端,执行以下命令
```shell:no-line-numbers
uv run fba init --auto
```
@tab 手动
1. 创建数据库:`fba`
* PostgreSQL 用户直接创建
* MySQL 用户创建时需选择 utf8mb4 编码
2. env
在 `backend` 目录打开终端,执行以下命令创建环境变量文件
```shell:no-line-numbers
cp .env.example .env
```
3. 按需修改配置文件:`backend/core/conf.py` 和 `.env`
4. 安装依赖
::: code-tabs
@tab uv - sync
```shell:no-line-numbers
uv sync
```
@tab uv - pip
```shell:no-line-numbers
uv pip install -r requirements.txt
```
:::
5. 创建数据库表和测试数据
::: tabs
@tab CLI
在 `根目录` 打开终端(确保已激活虚拟环境),执行以下命令
```shell:no-line-numbers
fba init
```
@tab Alembic + 手动
1. 在 `根目录` 打开终端(确保已激活虚拟环境),执行以下命令
生成迁移文件
```shell:no-line-numbers
fba alembic revision
```
执行迁移
```shell:no-line-numbers
fba alembic upgrade
```
2. 初始化测试数据
架构:执行 `backend/sql/` 目录下对应主键模式的脚本
插件:执行 `backend/plugin/sql/` 目录下对应主键模式的脚本
```shell:no-line-numbers
fba --sql 脚本文件路径
```
:::
5. 启动
在 `根目录` 打开终端(确保已激活虚拟环境),执行以下命令
```shell:no-line-numbers
fba run
```
6. 启动 celery worker, beat 和 flower
在 `根目录` 打开终端(确保已激活虚拟环境),执行以下命令启动 celery 相关服务
::: code-tabs
@tab Worker
```shell:no-line-numbers
fba celery worker
```
@tab Beat
```shell:no-line-numbers
fba celery beat
```
@tab Flower
```shell:no-line-numbers
fba celery flower
```
:::
::: warning
如果从未执行过以上命令,任务结果表将缺失,此时,无论从何处调用任务结果相关接口都会直接报错,直到至少启动一次 worker 和
beat 服务,相关接口将自动恢复正常
:::
7. 打开浏览器访问:
::::
## 开发流程
::: note
仅供参考,实际以个人开发习惯为准
:::
::: steps
1. 定义数据库模型([model](../reference/model.md))
2. 定义数据验证模型([schema](../reference/schema.md))
3. 定义路由([router](../reference/router.md))
4. 编写业务(service)
5. 编写数据库操作([crud](../reference/CRUD.md))
:::
## 单元测试
::: info
通过 `pytest` 运行单元测试,项目内仅提供了非常简易的 demo,并不是完整单元测试,如需要,请自行编写
:::
::: steps
1. 创建测试数据库 `fba_test`,选择 utf8mb4 编码,PostgreSQL 用户可忽略编码
2. 创建数据库表,利用工具创建 `fba` 库所有表的 DDL 脚本,再通过 `fba_test` 库执行
3. 初始化测试数据,通过 `backend/sql/` 目录下对应主键模式的脚本初始化测试数据
4. 在项目根目录打开终端,执行以下单元测试命令
```shell:no-line-numbers
pytest -vs --disable-warnings
```
:::
---
---
url: /fastapi_best_architecture_docs/backend/summary/slim.md
---
# 精简版本
FastAPI 最佳架构精简版的目标是仅保留最最最简单的架构代码,使其更易扩展
## SQLAlchemy
::: caution
此版本的更新非实时不同步,我们目前正在寻找维护人员
:::
## Tortoise-ORM
::: caution
此版本的更新非实时不同步,我们目前正在寻找维护人员
:::
---
---
url: /fastapi_best_architecture_docs/backend/summary/why.md
---
# 为什么选择我们?
> \[!TIP]
> 此仓库作为模板库公开,任何个人或企业均可自由使用!
> \[!IMPORTANT]
> 我们不会去对比任何其他架构,我们认为每个架构都有自己的特点,适用于不同的场景。
>
> 但 ==fba 绝对是开源架构中,代码最整洁,最规范且最令人赏心悦目的项目之一=={.tip}
## 目标
我们的目标是提供一个最佳架构,让开发者可以快速上手,能够专注于业务逻辑开发,或从此架构中获得灵感,优化本地架构设计,所以我们只会不断完善和优化我们的架构,为开发者带来更好的体验
## 承诺
此仓库作为模板库公开,任何个人或企业均可自由使用!您可以通过 [定价页面](../../pricing.md) 选择不同版本
## 架构
独一无二,自主研发,自主命名,开发人员可轻松驾驭的独特架构:[伪三层架构](../summary/intro.md#伪三层架构)
## 开放性
* MIT 协议 + 架构源码全量开源
* GitHub 模板仓库,便捷复制和自主命名
* 没有任何以 `fba` 强制命名的内容,也就是说,你可以通过 IDE 统一替换所有 `fba` 关键字为其他
## 灵活性
最具灵活性的代表就是我们的【插件系统】,不仅如此,在接口响应,错误定义,包括架构本身,我们一直在致力于使其既好用又简洁,这些设计对开发者非常友善
## 长期维护
自创建此项目以来,我们已为此项目付出了大量的时间,并且,这仍然在继续!

## 框架由来
我们有一个完整的关于 fba 由来的 [issues](https://github.com/fastapi-practices/fastapi_sqlalchemy_mysql/issues/5)
,但它被不小心永久删除且无法恢复 😭,我们尝试联系了 GitHub 支持,但不幸的是,我们仍无法获取完整 issues 😭
大致内容为我们的核心团队成员 [downdawn](https://github.com/downdawn) 在 fba 创建之前,找到了 fba
的前身仓库 [fastapi\_sqlalchemy\_mysql](fsm.md#sqlalchemy),并创建了 issue:【几点讨论与建议】;我们就此 issue
展开了为期数天的讨论,最终决定并创建了
fba
## 套件产物
在创建和迭代 fba 的同时,我们创建了很多与之相关的套件,且他们非常实用,并且我们做到了 0 耦合,您完全可以将它们用到其他与之相关的项目中去
::: center
[more...](https://github.com/orgs/fastapi-practices/repositories?)
:::
## 精简版
尽管我们在 fba
中尽可能地降低了耦合度,但是对于一个简易版本来讲,它需要删除太多东西,因此,我们同时提供了精简版本,详情请查看:[精简版](./fsm.md)
## 质量与规范
* 全局使用 reStructuredText 文档风格
我们采用了 rest 文档风格,这是一种非常流行的 Python 代码文档,并且,与 IDE 有非常好的集成
* 快速同步框架新特性
我们追求新事物,拥抱新事物,我们会积极跟进 FastAPI 中的新特性,在不受 Issue 影响的情况下,尽可能地将所有好用的新特性集成进来
* 严格的代码质量
我们有十分严格的 CI
代码质量检测和[规则](https://github.com/fastapi-practices/fastapi_best_architecture/blob/master/backend/.ruff.toml)
,使用非常流行且强大的 Ruff 作为支撑,为每次 PR 的代码质量做到严格把控
* 持续的认可
在此我们不做任何宣传引导,您可以在任意社区/交流群发出疑问,我们静待用户真实反馈
---
---
url: /fastapi_best_architecture_docs/blog/claude-ai-ecosystem.md
---
# Claude 智能体生态系统指南
Claude 的“智能体”(agentic)功能越来越强大,随着 **Skills**(技能)的推出,用户开始关注其生态系统中各个组件的角色与协作方式
## Projects(项目)
付费计划专属的自包含工作空间,拥有独立聊天历史、200K 上下文窗口和知识库
### 工作机制
* 可上传文档作为知识库,Claude 在项目内所有对话均可访问
* 接近上限时自动启用 RAG(检索增强生成),有效扩展上下文
* 支持自定义项目指令,适用于所有子对话
### 适用场景
* 需要持久背景知识的项目(如产品发布、研究专题)
* 团队协作(共享知识库)
* 为特定领域设定统一语气、视角或方法
**示例**:创建一个“Q4 产品发布”项目,上传相关文档,设置指令“从产品策略角度分析竞争对手,提出差异化建议”。所有后续对话自动遵循
## Skills(技能)
Skills 是一个“文件夹”,包含指令、脚本和资源文件。Claude 在处理任务时会动态扫描并加载相关 Skills
### 工作机制
* 采用渐进披露设计:先加载元数据(约 100 tokens)判断相关性,再加载完整指令(通常 < 5k tokens),脚本或文件仅在必要时加载。
* 这避免了上下文窗口被无关内容占满
### 适用场景
* 需要持久、一致的专业能力时
* 公司品牌指南、合规流程、领域专家知识(如 Excel 高级操作、PDF 处理)
* 个人偏好(如编码风格、笔记系统)
**优势**:可复用、可移植,多个对话或子智能体都能共享
**示例**:创建一个“品牌指南”Skill,包含颜色、字体、布局规范。此后所有生成内容自动遵守标准,无需重复说明
## MCP(Model Context Protocol)
一种开放标准协议,用于将 Claude 连接到外部工具和数据源(如 Google Drive、GitHub、数据库、CRM)
### 作用
* 提供持久的外部数据访问,而非每次手动上传
* 类比互联网时代的 HTTP/API,是 AI 时代的“连接器”
**与 Skills 的关系**:
* MCP 负责连接与数据获取(原子能力)
* Skills 负责处理逻辑与流程(SOP 化指导)
两者互补:MCP 提供工具,Skills 指导如何使用
**适用场景**:需要频繁访问外部系统或集成企业工具时
## Subagents(子智能体)
拥有独立上下文、系统提示和工具权限的专用助手。主要在 Claude Code 或 Agent SDK 中使用
### 适用场景
* 任务专业化(如代码审查、测试生成)
* 隔离复杂子任务,保持主对话简洁
* 并行处理或限制工具权限(例如只读不写,提高安全性)
**与 Skills 的区别**:
* Subagents 更像“专属员工”,适合特定工作流
* Skills 更像“通用教材”,适合跨对话共享专业知识
## Prompts(提示词)
对话中直接输入的自然语言指令,短暂且对话式
### 适用场景
* 一次性任务(如总结文章)
* 实时调整(如“语气更专业”)
* 临时上下文或格式要求
**特点**:不跨会话持久化。如果同一类指令频繁重复,建议升级为 Skill 或 Project 指令
## 各组件如何协同
* **Project** 提供持久上下文和知识库
* **Skills** 注入可复用的专业知识和处理规范
* **MCP** 连接外部实时数据源
* **Subagents** 分担专业子任务
* **Prompts** 用于实时微调
### 实际案例
《构建竞争情报智能体》
* 创建 **Project**,上传历史报告,设置统一分析指令
* 创建 “竞争分析” **Skill**,定义文档检索策略和输出模板
* 通过 **MCP** 连接 Google Drive 和 Web 搜索
* 设置两个 **Subagents**:市场研究员(趋势分析)和技术分析师(产品对比)
* 用户只需一个 **Prompt** 启动:“分析前三大竞争对手的 AI 功能,找出突破机会”
**结果**:Claude 自动协调多源数据、专业方法、子任务分工,输出结构化、高质量报告
## 总结建议
* 持久项目上下文 → 用 **Projects**
* 重复性专业知识 → 封装为 **Skills**(最高复用性)
* 外部工具集成 → 用 **MCP**
* 任务隔离与并行 → 用 **Subagents**
* 临时调整 → 用 **Prompts**
合理组合这些模块,能大幅提升 Claude 在个人效率、企业流程、复杂代理工作流中的表现。未来随着生态成熟,更多标准化工具与 Skills
将进一步简化智能体构建
---
---
url: /fastapi_best_architecture_docs/blog/contextvar.md
---
在异步编程和并发场景中,如何优雅地管理上下文相关的状态变量?传统的全局变量容易导致状态污染,而线程本地存储(
`threading.local`)又不适合异步任务的嵌套执行
`ContextVar` 正是为此而生,它允许在同一个线程中,根据不同的执行上下文(如协程或任务)持有不同的变量值,而无需显式传递参数
## 什么是 ContextVar?
`ContextVar` 是 `contextvars` 模块的核心类,用于声明和管理上下文变量。它类似于线程本地存储,但专为异步执行环境设计。在
Python 的异步框架如 `asyncio` 中,多个协程可能在同一线程中并发运行,如果使用全局变量,状态很容易在任务间“泄露”。`ContextVar`
通过维护一个每个线程的上下文栈来解决这个问题:每个上下文(`Context` 对象)可以持有变量的快照,进入新上下文时会推入栈顶,退出时自动回滚。
简单来说,`ContextVar` 让你在代码中隐式访问上下文特定的值,比如当前请求的日志追踪 ID,而不用层层传递参数。这在
Web 框架(如 FastAPI 或 Starlette)中特别常见。
## 核心类和方法
`contextvars` 模块主要包含三个类:`ContextVar`、`Token` 和 `Context`。下面是它们的简要说明:
### ContextVar
用于声明上下文变量
* 构造函数:`ContextVar(name, default=None)`,其中 `name` 是字符串用于调试,`default` 是默认值
* 方法:
* `get(default=None)`:获取当前上下文的值,如果未设置则返回 `default` 或抛出 `LookupError`
* `set(value)`:设置当前上下文的值,返回一个 `Token` 对象用于回滚
* `reset(token)`:使用 `Token` 恢复上一个值
### Token
`set()` 返回的对象,用于追踪和恢复变量的旧值
它有属性如 `old_value`(旧值)和 `var`(关联的 `ContextVar`)。从 Python 3.14 开始,`Token` 支持上下文管理器协议,便于使用
`with` 语句
### Context
表示一个上下文映射(类似于字典),管理变量的状态
* `copy_context()`:复制当前上下文(O(1) 复杂度)
* `run(callable, *args, **kwargs)`:在指定上下文中执行可调用对象,执行后自动回滚变化
## 基本使用示例
假设我们有一个名为 `user_id` 的上下文变量,用于追踪当前用户的 ID。
```python
import contextvars
# 声明上下文变量,设置默认值
user_id = contextvars.ContextVar('user_id', default='anonymous')
# 获取当前值
print(user_id.get()) # 输出: anonymous
# 设置新值,返回 Token
token = user_id.set('alice')
print(user_id.get()) # 输出: alice
# 使用 Token 回滚
user_id.reset(token)
print(user_id.get()) # 输出: anonymous
```
再看一个使用 `Token` 作为上下文管理器的例子(Python 3.14+):
```python
user_id = contextvars.ContextVar('user_id', default='anonymous')
with user_id.set('bob'):
print(user_id.get()) # 输出: bob
# 在 with 块内,所有访问都会看到 'bob'
print(user_id.get()) # 输出: anonymous(自动回滚)
```
这比手动 `reset` 更安全,避免了遗忘回滚的风险
## 在异步编程中的应用
`ContextVar` 的真正威力在异步环境中显现。以 `asyncio` 为例,我们可以构建一个简单的回显服务器,其中每个客户端连接的地址存储在上下文中,其他函数无需参数即可访问
```python
import asyncio
import contextvars
# 声明任务 ID 变量
task_id_var = contextvars.ContextVar('task_id', default='none')
async def sub_task():
# 无需传递参数,直接从上下文中获取
task_id = task_id_var.get()
print(f"Sub task running with task_id: {task_id}")
await asyncio.sleep(0.1) # 模拟工作
async def main_task(task_id):
token = task_id_var.set(task_id)
try:
await sub_task()
finally:
task_id_var.reset(token)
async def main():
# 并发运行多个任务
await asyncio.gather(
main_task('task1'),
main_task('task2')
)
# 运行示例
asyncio.run(main())
```
运行这个代码,你会看到输出:
```text
Sub task running with task_id: task1
Sub task running with task_id: task2
```
在这个例子中,sub\_task() 函数无需知道任务 ID,就能从当前上下文中读取它。即使在 asyncio.gather
的并发执行中,每个任务的值也会正确隔离,不会与其他任务混淆。这比显式传递参数更简洁,尤其在深层嵌套的异步调用链中
另一个常见场景是日志追踪:在 ASGI 应用中,将请求 ID 存入 `ContextVar`,然后在任何下游函数中自动注入到日志中
## 与 threading.local 的区别
`threading.local` 提供线程本地存储,每个线程有独立的变量副本,适合多线程程序。但在异步代码中,所有协程共享同一线程,导致
`local` 值在任务间泄露
`ContextVar` 则基于执行上下文栈,支持协程的嵌套和切换:每个任务或生成器有自己的视图,变化在退出时自动回滚
简单比较:
| 特性 | ContextVar | threading.local |
|------|------------------------|-----------------|
| 适用场景 | 异步/协程(asyncio) | 多线程 |
| 隔离粒度 | 执行上下文(任务/生成器) | 线程 |
| 回滚机制 | 自动(通过 Token 或 Context) | 无需回滚,线程隔离 |
| 性能开销 | 低(O(1) 复制) | 低 |
如果你在用 `asyncio`,优先选择 `ContextVar`
## 注意事项
* **创建位置**:始终在模块顶层创建 `ContextVar`,避免在闭包或函数内创建,否则可能导致内存泄漏(上下文持有强引用)
* **默认值**:使用 `default` 参数避免 `LookupError`,但在异步中要小心默认值的共享
* **兼容性**:Python 3.7+ 支持,原生集成 `asyncio`。在多线程中,每个线程有独立栈
* **调试**:通过 `name` 属性和 `Context.items()` 检查变量状态
---
---
url: /fastapi_best_architecture_docs/blog/custom-exception.md
---
# FastAPI 如何自定义异常
我们为 fba 精心设计了全局异常拦截器,它可以自动拦截所有异常信息,并按照标准化的返回信息进行异常信息返回
## 异常拦截器
在异常拦截器中,我们按照标准错误码进行错误处理
在响应中,我们存在两种状态码,分别为返回信息中的状态码和响应状态码;其中,响应状态码默认为编码级,前端完全可以根据此状态码进行异常处理页面跳转,例如,403(无权限操作),404(资源不存在)等等,而返回信息状态码为自定义级,可以在返回时任意自定义
响应状态码遵循 RFC 定义,如果不符合标准,则将状态码处理为 400
```python
def _get_exception_code(status_code: int) -> int:
"""
获取返回状态码(可用状态码基于 RFC 定义)
`python 状态码标准支持 `__
`IANA 状态码注册表 `__
:param status_code: HTTP 状态码
:return:
"""
try:
STATUS_PHRASES[status_code]
return status_code
except Exception:
return StandardResponseCode.HTTP_400
```
异常拦截器还包含:fastapi 数据校验异常,pydantic 数据校验异常,python assert 断言异常,全局未知(未定义)异常,跨域异常,自定义异常,详情请查看:
`backend/common/exception/exception_handler.py`
## 后台任务
了解完异常处理器之后,再来讲讲如何自定义异常,我们先看下面这段代码,这是自定义异常的
```python
class BaseExceptionMixin(Exception):
code: int
def __init__(self, *, msg: str = None, data: Any = None, background: BackgroundTask | None = None):
self.msg = msg
self.data = data
# The original background task: https://www.starlette.io/background/
self.background = background
```
在这段代码中,我们有一个参数为 `background`(由于 fastapi 继承了 starlette,这意味者,fastapi 拥有 starlette
中的所有功能,所以,这里的注释,我们直接导航到了 starlette),它可以让我们添加后台任务,这遵循了 starlette 的后台任务处理,所以,你不仅可以使用
fastapi 中的后台任务定义方式,还完全可以使用 statlette 中的后台任务定义方式
请注意 ==后台任务应附加到响应,并且仅在发送响应后才运行=={.tip}
,这非常重要!并且,任务按顺序执行。如果其中一个任务引发异常,则后面的任务将没有机会执行。所以,我们只推荐为极小的任务使用此方式进行处理!
## 自定义异常
上方我们已经介绍完了自定义异常中包含的其他附加业务,下方我们来讲下如何自定义异常,在文件
`backend/common/exception/errors.py` 中,我们内置了多种自定义异常类,它们结构基本相当,例如:
```python
class NotFoundError(BaseExceptionMixin):
code = StandardResponseCode.HTTP_404
def __init__(self, *, msg: str = 'Not Found', data: Any = None, background: BackgroundTask | None = None):
super().__init__(msg=msg, data=data, background=background)
```
这是我们经常使用的错误类之一,其中,参数 `code` 被定义为编码级响应状态码,参数 `msg`、`data` 对应在返回信息中,fba
会在内部自动处理,参数 `background` 正式我们上方所讲的后台任务
我们来动手试着定义一个:
```python
class 自定义错误类(BaseExceptionMixin):
code = 遵循 RFC 定义的响应状态码
def __init__(self, *, msg: str = '自定义', data: Any = None, background: BackgroundTask | None = None):
super().__init__(msg=msg, data=data, background=background)
```
## 如何使用
使用方式非常简单,我们在 fba 代码内任意位置直接使用 `raise errors.xxxError(msg='xxx')` 即可,自定义异常会在异常处理器中自动处理并返回
---
---
url: /fastapi_best_architecture_docs/blog/git-emoji.md
---
# Git:为提交信息添加表情符号
在 git 提交信息中受支持的 emoji
## 使用
**输入:**
```sh:no-line-numbers
git commit -m "feat: :rocket: add new feature"
```
**输出:**
```txt:no-line-numbers
feat: 🚀 add new feature
```
## emoji 列表
---
---
url: /fastapi_best_architecture_docs/blog/header-token.md
---
在 FastAPI 官方高级安全教程中,为我们介绍了两种授权方式,分别是 OAuth2 scopes 和 HTTP Basic Auth,两种方式都可以实现
Swagger 文档授权,并且可以在文档界面通过直接登录的方式进行快捷授权
以上两种方式虽然可以实现文档内快捷验证,但是它们都使用了表单登录方式,这对于我们来说,并不是一个理想的方案,所以我们在 fba
中使用了 HTTPBearer,这种方式相对于前两种,不够便捷,但同样可以实现文档内自动授权,需要我们先访问登录接口获取 token,然后填入即可
## 为什么是 Bearer Token?
在实际工作中,诸多情况可能都不会使用 bearer token 这种方式,虽然,很多的系统也在使用 token 进行授权,但往往授权方式五花八门,那为什么是
bearer
token?答案是,没有为什么,这只是一种标准方案,可参考文档:[Authentication Schemas ](https://developer.mozilla.org/en-US/docs/Web/HTTP/Authentication#authentication_schemes)
对于我们常规使用的接口工具,例如 Postman、APIfox 等来讲,它们也都实现了 bearer 这种标准授权方式,可以轻松实现自动授权,具体请以官方教程为准
## 自定义 Token 授权方式
好了,上面扯了那么多,回到正题,如何使用非 bearer token 这种方式,而是设置一个自定义请求头实现授权(这里插一句,本身,怎么实现对于后端来说无所谓,如果前端要求
xxx 实现授权才行,那纯属它们懒,如果是技术规格要求,那就再议)
首先,进入 `backend/common/security/jwt.py` 文件中,找到 `DependsJwtAuth = Depends(HTTPBearer())`,将 `HTTPBearer()` 替换为
`APIKeyHeader(name='xxx')`,name 就是我们的自定义请求头 key;由于我们使用的是 bearer 方式,你还需要修改同文件下的
`get_token()` 方法,如下所示:
```python
def get_token(request: Request) -> str:
authorization = request.headers.get('xxx') # name
if not authorization:
raise TokenError(msg='Token 无效')
return token
```
修改 JWT 中间件,如下所示:
```python
# 删除以下代码
scheme, token = get_authorization_scheme_param(token)
if scheme.lower() != 'bearer':
return
```
至此,你已完成自定义 token 授权,在文档中进行授权时,同样需要你需要先登录获取 token,然后填入
但是这种授权方式,对于接口工具来讲,我们则需要手动在请求头中加入 token,而无法实现自动授权,所以,个人还是比较建议使用标准实施
---
---
url: /fastapi_best_architecture_docs/blog/jwt-middleware.md
---
# FastAPI 为什么使用 JWT 认证中间件
在构建现代 Web 应用时,安全认证是不可或缺的一环。今天,让我们一起来看看 fba 项目中的 JWT 认证中间件:
`backend/middleware/jwt_auth_middleware.py` 的实现,这将是我们在企业级项目中可应用的最佳实践
## 它解决了什么问题?
如果你正在开发一个需要用户登录的 API 服务,你需要:
* 验证用户身份
* 保护敏感接口
* 在请求间保持用户状态
* 优雅地处理认证失败
* ......
传统方案往往需要你在每个接口中重复编写认证逻辑,或者使用装饰器来包装路由函数,而我们的 JWT 中间件则提供了一种更优雅的集成方式:一次配置,全局生效
## 如何使用它?
例如在 fba 中,我们提供了中间件的统一注册入口:
```python
def register_middleware(app: FastAPI) -> None:
# ...其他中间件
app.add_middleware(
AuthenticationMiddleware, # 来自 starlette 的认证中间件
backend=JwtAuthMiddleware(), # 重写为自定义中间件
on_error=JwtAuthMiddleware.auth_exception_handler, # 重写为自定义错误
)
```
然后在你的路由函数中,就可以直接通过 `request.user` 获取当前登录用户的信息,如下所示:
```python
@router.get("/profile")
async def get_profile(request: Request):
# 用户信息已经由中间件注入到请求对象中
current_user = request.user
return {"user": current_user}
```
我们可以看到,既没有繁琐的依赖注入,也没有重复的认证代码,一切都变得如此简洁
## 与 FastAPI 官方实现的不同之处
FastAPI 官方推荐使用 `OAuth2PasswordBearer` 和依赖注入系统来实现 JWT 认证
```python
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
@router.get("/users/me")
async def get_profile(current_user: User = Depends(get_current_user)):
return current_user
```
这与我们的 JWT 认证中间件相比吗,看起来只是少了几行代码,但背后的差异却很大:
1. **全局一致性** :中间件确保了所有请求都经过相同的认证流程,避免了遗漏
2. **错误处理统一** :自定义的错误处理器确保了所有认证失败都返回一致的响应格式
3. **代码简洁** :路由函数不再需要显式依赖认证逻辑,关注点更加分离
4. **灵活扩展** :中间件架构使得添加新的认证方式或权限检查变得简单
## 为什么推荐 JWT 中间件?
在实际项目中,这种基于中间件的 JWT 认证方案有几个明显优势:
### 对开发者友好
fba 一向注重在这方面考量,而使用此中间件,新加入团队的开发者就不再需要了解复杂的认证机制,只需知道 `request.user`
中包含当前用户信息即可。这大大降低了入门门槛,减少了潜在的安全漏洞
### 统一的错误处理
所有认证相关的错误都通过同一个处理器处理,确保了 API 响应的一致性。无论是 Token 过期还是格式错误,客户端都能收到格式统一的错误信息
### 性能考量
中间件只在必要时执行认证逻辑,对于白名单中的路径(如登录接口、健康检查...)会自动跳过,避免了不必要的性能开销,并且还使用
Redis 和 Rust 库对用户信息进行缓存和解析,使其性能影响尽可能降到最低
## 注意事项
这个中间件设计得足够灵活,可以根据项目需求进行多种扩展,但中间件会应用于每个 API 请求(非认证请求和白名单 API
除外),所以一定要考虑扩展功能的适用性和性能
---
---
url: /fastapi_best_architecture_docs/blog/middleware.md
---
# FastAPI 如何编写自定义中间件
在编写中间件之前,我们首先要对中间件有一些了解
## 什么是中间件?
中间件是一种可以自定义处理请求和响应的机制,这种机制可以自动应用于每个请求;
工作机制:当在应用程序中发送一个请求时,会在接口路径(可以理解为接口函数)代码执行前获取它,你可以对此请求进行自定义逻辑处理,然后将处理过的请求再交给接口路径继续执行,在接口响应返回前,你也可以提前获取响应,并对响应进行自定义逻辑处理
在编写自定义中间件时,很多佬可能存在误区,比如:我编写了一个处理请求的普通日志函数,并放到了中间件目录作为中间件;错!这并不是一个中间件,而只是一个工具!它不应该被放到中间件目录,而是应该放到中间件文件中或工具目录中
## 如何编写?
中间件的编写方法有三种
### BaseHTTPMiddleware
这种编写方法相对简单
```python
class AccessMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request: Request, call_next: RequestResponseEndpoint) -> Response:
start_time = timezone.now()
response = await call_next(request)
end_time = timezone.now()
print(f'time: {end_time - start_time}')
return response
```
编写此类中间件,首先,你要继承 `BaseHTTPMiddleware`,然后重写异步函数:`dispatch()`,在此函数中,`call_next(request)`
之前的代码就是接口路径代码执行前的逻辑处理,之后的代码就是在响应被返回前的逻辑处理,最后,返回响应,至此,你已完成编写自定义中间件
### 纯 ASGI
这种编写方式相对比较复杂
```python
class ASGIMiddleware:
def __init__(self, app):
self.app = app
async def __call__(self, scope, receive, send):
await self.app(scope, receive, send)
```
这里包含 [ASGI 规范](https://www.starlette.io/middleware/#pure-asgi-middleware)
,除非经过系统性学习,否则,你不能完成编写此类自定义中间件
### 装饰器
这种方式看起来很好,并且是 fastapi 的官方教程,但这不适用于 fba
```python
@app.middleware("http")
async def add_process_time_header(request: Request, call_next):
start_time = timezone.now()
response = await call_next(request)
end_time = timezone.now()
print(f'time: {end_time - start_time}')
return response
```
## 如何使用
进入 fba 项目,找到 `backend/core/registrar.py`,在此文件中找到 `register_middleware()` 函数,这是 fba 的中间件注册函数
在此函数中,==中间件按照从上往下的顺序依次执行==,因此,中间件的顺序非常重要
上面我们提到过使用装饰器编写中间件,但不适用于 fba,经过查看 fastapi 源码,我们发现,此装饰器的本质就是在内部调用了
`add_middleware()` 函数,所以,我们可以直接通过 `app.add_middleware()` 将中间件类添加到应用程序中,这种方式也更符合 fba
当前的编码风格
---
---
url: /fastapi_best_architecture_docs/blog/operator.md
---
# FastAPI 如何添加操作人信息
我们常见的后台管理系统中,经常会有一些比如创建人,更新人这类的信息,那这些信息是如何做的呢?下面我们就来讲一讲我们在 fba
中应该如何集成操作人信息
## 如何集成?
打开 fba 项目,进入 `backend/common/model.py` 文件中,你会看到 `UserMixin` 类就冰冷冷的站在那里,因为 fba
没有使用它,而只是保留它;
```python
class UserMixin(MappedAsDataclass):
"""用户 Mixin 数据类"""
created_by: Mapped[int] = mapped_column(sort_order=998, comment='创建者')
updated_by: Mapped[int | None] = mapped_column(init=False, default=None, sort_order=998, comment='修改者')
```
## 如何使用?
首先,`UserMixin` 类所存储的信息只是用户的 id ,这也是一种常见的做法,那么问题来了:我该如何获取用户 id 并存储?
我在后台展示的时候,肯定不能展示 id 吧?容我一一解答
## 如何获取用户 ID?
fba 通过 JWT 中间件将用户信息存储到了每个请求的上下文中,我们可以很轻松的通过 request 对象读取用户信息(在 Django,Flask
等 Web 框架中, request 都是常驻嘉宾)
## 如何存储?
### 手动
首先,在接口函数中,传入一个 `request` 参数,最好,我们加上参数类型:`request: Request`,然后我们可以在接口函数中通过
`request.user.id` 获取当前操作人员 id ,然后传递此 id 进行存储
除此之外,为了简化代码,我们还可以通过 `ctx.user_id` 直接获取操作人员 id 进行存储
### 自动
利用 SQLAlchemy 的事件监听,我们可以轻松做到这一点
首先,我们需要对 UserMixin 做些调整:
```python{4}
class UserMixin(MappedAsDataclass):
"""用户 Mixin 数据类"""
created_by: Mapped[int] = mapped_column(init=False, sort_order=998, comment='创建者')
updated_by: Mapped[int | None] = mapped_column(init=False, default=None, sort_order=998, comment='修改者')
```
然后在 `backend/common/model.py` 底部添加添加以下监听事件:
```python
@event.listens_for(UserMixin, 'before_insert', propagate=True)
def set_created_by(mapper, connection, target) -> None: # noqa: ANN001
if hasattr(target, 'created_by'):
target.created_by = ctx.user_id
@event.listens_for(Session, 'do_orm_execute', propagate=True)
def set_updated_by(orm_statement: ORMExecuteState) -> None:
if (
orm_statement.is_update
and orm_statement.is_orm_statement
and orm_statement.statement.is_update
and orm_statement.bind_mapper.c.get('updated_by') is not None
):
orm_statement.statement = orm_statement.statement.values(updated_by=ctx.user_id)
```
::: warning
before\_insert 事件需配合 `flush()` 才能触发!
事件监听条件要求严格,如果监听事件未按预期执行,参考:[sqlalchemy#12724](https://github.com/sqlalchemy/sqlalchemy/discussions/12724)
:::
## 如何展示?
当然不能,那该怎么办呢?虽然我们只存储了用户 id 到数据库,但当我们单查询或列表查询的时候,我们需要进行数据拦截,将 id 替换为
username;
这会涉及到另外的问题,username 从哪里来?考虑到性能影响,我们如果每次都遍历这些 id 去查询数据库进行替换,无疑是增加了大量 IO
操作,因此,我们可以埋点(新用户注册后,查询用户列表时...)将所有用户 id 和 username 缓存到 redis,替换的时候就直接读取缓存
## 直接存成 username 不更好么?
当然可以,你可以直接修改 `UserMixin` 存为字符串,然后直接通过 `request.user.username` 存储用户名,这样查询出来就直接是用户名,从而无需再进行替换操作
## 到底存什么?
用 id 还是用 username,取决于业务场景;如果需要总是显示最新用户信息,避免用户更新用户名之后还需要更新所有历史数据,则使用
id,如果 username 是唯一的,并且需要保留历史痕迹,直接用 username 即可
---
---
url: /fastapi_best_architecture_docs/blog/pydantic-validator.md
---
## 内置约束参数
这些是最常用的简单约束,直接在 `Field` 中传递
| 参数名 | 描述 | 适用类型 | 示例用法 |
|------------------|-------------------|--------------------------------|------------------------------|
| `min_length` | 最小长度 | str, bytes, list, tuple, set 等 | `Field(min_length=3)` |
| `max_length` | 最大长度 | str, bytes, list, tuple, set 等 | `Field(max_length=50)` |
| `pattern` | 正则表达式匹配(等同 regex) | str | `Field(pattern=r'^[a-z]+$')` |
| `gt` | 大于(greater than) | int, float, Decimal | `Field(gt=0)` |
| `ge` | 大于等于 | int, float, Decimal | `Field(ge=18)` |
| `lt` | 小于 | int, float, Decimal | `Field(lt=100)` |
| `le` | 小于等于 | int, float, Decimal | `Field(le=120)` |
| `multiple_of` | 必须是指定值的倍数 | int, float, Decimal | `Field(multiple_of=5)` |
| `min_items` | 序列最小元素数 | list, tuple, set 等 | `Field(min_items=1)` |
| `max_items` | 序列最大元素数 | list, tuple, set 等 | `Field(max_items=10)` |
| `strict` | 严格模式(禁止类型自动转换) | 所有类型 | `Field(strict=True)` |
| `max_digits` | Decimal 最大位数 | Decimal | `Field(max_digits=10)` |
| `decimal_places` | Decimal 小数位数 | Decimal | `Field(decimal_places=2)` |
## 约束类型
更声明式的写法,等价于上面的 `Field` 参数
| 约束标记 | 描述 | 适用类型 | 示例用法 |
|------------------|------------|----------------------|----------------------------------------|
| `Gt(value)` | 大于 value | int, float, Decimal | `Annotated[int, Gt(0)]` |
| `Ge(value)` | 大于等于 value | int, float, Decimal | `Annotated[int, Ge(18)]` |
| `Lt(value)` | 小于 value | int, float, Decimal | `Annotated[int, Lt(100)]` |
| `Le(value)` | 小于等于 value | int, float, Decimal | `Annotated[int, Le(120)]` |
| `Len(min, max)` | 长度范围 | str, bytes, list 等序列 | `Annotated[str, Len(3, 50)]` |
| `Pattern(regex)` | 正则匹配 | str | `Annotated[str, Pattern(r'^[a-z]+$')]` |
其他常用 Annotated 工具:
* `InstanceOf[T]`:检查是否为指定类的实例
* `SkipValidation`:跳过验证(用于已信任数据)
## 自定义字段验证器
| 类型/方式 | 模式(mode)选项 | 描述 | 示例场景 |
|-------------------------|-------------------------------------|-------------------|---------------|
| `@field_validator` | `after`(默认)、`before`、`plain`、`wrap` | 装饰器式,针对单个或多个字段 | 密码哈希、复杂格式检查 |
| `BeforeValidator(func)` | before | 函数式:在解析前运行 | 输入预处理、None 处理 |
| `AfterValidator(func)` | after | 函数式:在类型验证后运行 | 业务规则检查 |
| `PlainValidator(func)` | plain | 函数式:完全自定义,跳过内置验证 | 自定义类型解析 |
| `WrapValidator(func)` | wrap | 函数式:最灵活,可手动调用内置验证 | 复杂逻辑、自定义错误 |
## 模型级验证器
| 类型 | 模式(mode)选项 | 描述 | 示例场景 |
|--------------------|-------------------------|--------------|-------------|
| `@model_validator` | `after`、`before`、`wrap` | 针对整个模型的跨字段验证 | 密码确认、字段依赖检查 |
## 可选字段(非必填)的验证注意事项
可选字段通常这样定义:
```python
username: str | None = None
# 或
username: str | None = Field(default=None, ...)
```
### 默认行为
* **内置约束**:当值为 `None` 时,完全跳过约束检查;只有提供非 `None` 值时才验证
* **自定义验证器**(`@field_validator` 或函数式):默认在值为 `None` 或使用默认值时**不运行**
### 常见坑点
1. 以为 `min_length=3` 会对 `None` 报错 → 其实不会
2. 自定义验证器不触发,导致逻辑遗漏(尤其是想对 `None` 做特殊处理时)
3. 从 V1 迁移:V1 有 `always=True`,V2 已移除
### 推荐解决方案
1. 大多数情况直接用默认行为(推荐):
```python
username: str | None = Field(None, min_length=3)
```
2. 想对 `None` 做自定义处理 → 用 `WrapValidator`(最灵活):
```python
from pydantic import WrapValidator
def optional_validator(v: str | None, handler):
if v is None:
return None # 或 raise ValueError("不能为空") / return "default"
return handler(v) # 调用内置验证
username: Annotated[str | None, WrapValidator(optional_validator)] = None
```
3. 强制验证默认值(少用):
```python
model_config = {"validate_default": True}
```
4. **预处理 None** → 用 `BeforeValidator`:
```python
def none_to_empty(v: str | None) -> str:
return v or ""
username: Annotated[str, BeforeValidator(none_to_empty), Field(min_length=1)] = ''
```
## 总结
Pydantic V2 的验证系统强大而灵活:
* 简单场景 → 内置约束 + Annotated
* 复杂逻辑 → 函数式/装饰器验证器 + Wrap 模式
* 可选字段 → 默认行为已很智能,需要特殊处理时用 WrapValidator
---
---
url: /fastapi_best_architecture_docs/blog/typing-cast.md
---
在 Python 3.5 引入类型提示以来,渐进式类型系统让我们的代码更易维护、更易协作。但类型检查器有时太“聪明”了,会因为动态数据或第三方库而迷失方向。
`typing.cast` 就像一个“类型声明器”,帮你明确告诉检查器:“嘿,这个值就是这个类型,别多想了!”
## 什么是 typing.cast
`typing.cast` 是 Python 标准库 `typing` 模块中的一个辅助函数。它的核心作用是**在静态类型检查阶段“强制”指定一个值的类型**
,但在运行时,它什么都不做——只是原封不动地返回输入的值。 这设计非常巧妙:它确保了零运行时开销,同时提升了代码的静态安全性
简单来说:
* **静态时**:类型检查器(如 mypy)会认为返回值就是你指定的类型,从而正确推断后续代码
* **运行时**:Python 继续它的鸭子类型哲学,一切照旧
这不同于真正的类型转换(如 `int("123")`),它更像是一个“类型断言”,专为类型提示生态设计
## 如何使用 typing.cast
使用 `typing.cast` 非常简单。它的签名是:
```python
from typing import cast
result = cast(目标类型, 值)
```
* `目标类型`:可以是任何有效的类型提示,如 `int`、`List[str]`、`Optional[Dict[str, int]]` 等
* `值`:你要“转换”的对象,运行时它不会变
让我们通过几个例子来看看它怎么玩转类型提示。
### 示例 1:处理 Any 类型
`Any` 类型是类型提示中的“万金油”,但它会让类型检查器变得宽松。假如你从外部 API 获取数据,知道它其实是 `List[int]`,但检查器只看到
`Any`:
```python
from typing import Any, cast, List
def process_scores(data: Any) -> List[int]:
# 假设我们已经验证了 data 是整数列表
scores: List[int] = cast(List[int], data)
return [score * 2 for score in scores] # 现在检查器知道 scores 是 List[int],不会报错
# 使用
raw_data = [1, 2, 3] # 来自 API 的数据
doubled = process_scores(raw_data)
```
没有 `cast`,mypy 可能会抱怨 `scores` 的类型不明,导致后续列表推导式报错
### 示例 2:从 object 窄化类型
有时函数参数是 `object`(Python 的万能基类),但你知道具体类型:
```python
from typing import cast
def get_length(item: object) -> int:
# 假设 item 已被检查为 str
length: int = len(cast(str, item)) # 告诉检查器:item 是 str
return length
# 使用
result = get_length("hello") # 运行正常,检查器也满意
```
### 示例 3:第三方库集成
集成像 `requests` 这样的库时,返回值往往是 `Any`。用 `cast` 可以快速窄化:
```python
import requests
from typing import cast, Dict, Any
response = requests.get("https://api.example.com/data")
data: Dict[str, int] = cast(Dict[str, int], response.json()) # 假设我们知道 JSON 是这个结构
total = sum(data.values()) # 检查器现在知道 data 是 Dict[str, int]
```
这些例子展示了 `cast` 如何在不改动运行逻辑的情况下,提升代码的可读性和工具支持
## 实际应用场景
`typing.cast` 最常出现在这些地方:
* **动态数据处理**:如 JSON 解析、配置文件读取
* **遗留代码迁移**:逐步添加类型提示时,桥接动态和静态部分
* **低级 API**:如 C 扩展或网络协议解析,类型不明显
* **测试与模拟**:mock 对象需要精确类型
在大型项目中,它能减少类型检查器的噪音,让开发者专注于真正的问题
## 注意事项
`cast` 虽然强大,但也有风险:
* **无运行时保护**:它不会验证类型,如果你的假设是错误的(如 `cast(int, "abc")`),运行时会炸锅
* **滥用风险**:过度使用会隐藏真实类型错误,降低代码质量。记住,它是“逃生舱”,不是日常工具
* **最佳实践**:优先用条件检查(如 `isinstance`)或更精确的类型提示。只有当检查器“顽固”时,才祭出 `cast`。另外,从 Python 3.11
开始,还有 `typing.assert_type` 可以辅助验证,但它也只在静态阶段生效
---
---
url: /fastapi_best_architecture_docs/community-open-source.md
---
# 社区开源
作者正在翘首以盼的等着投喂🥹,这里是你的 Show Time 时刻!
## Rust
## Go
## React
---
---
url: /fastapi_best_architecture_docs/frontend/deploy/docker.md
---
# Docker 部署
::: warning
此教程以 HTTPS 为例
:::
:::: steps
1. 拉取代码到服务器
将代码拉取到服务器通常采用 ssh 方式(更安全),当然你也可以选择使用 HTTP 方式,具体方式请根据个人自行决定
2. env
修改 `/apps/web-antd/.env.production` 中的 `VITE_GLOB_API_URL` 为域名地址(末尾不带斜杠)
3. 更新 nginx 配置
文件 `/scripts/deploy/nginx.conf` 中有相关注释说明,根据需要进行修改即可
4. 更新 `docker-compose` 脚本
脚本 `docker-compose.yml` 中有相关注释说明,根据需要进行修改即可
5. 执行一键启动命令
::: caution 必要条件
* 注释了 fba 后端 docker-compose 脚本中的 fba\_ui 容器
* 已经通过 docker-compose 构建 fba 后端
:::
在项目根目录中打开终端,执行以下命令
```shell:no-line-numbers
docker compose up -d --build
```
::::
---
---
url: /fastapi_best_architecture_docs/frontend/deploy/legacy.md
---
# 传统部署
::: steps
## 服务器
1. 准备 Nginx
以 Ubuntu 为例:
```shell
sudo apt update
sudo apt install nginx -y
```
2. 更新配置
将 [nginx.conf](https://github.com/fastapi-practices/fastapi_best_architecture_ui/blob/master/scripts/deploy/nginx.conf)
替换到 `/etc/nginx/nginx.conf`
## 本地
1. env
更新 `.env.production` 配置文件
2. 打包
```shell
pnpm build
```
3. 上传
将 `/apps/web-antd/dist` 目录下的所有文件上传到服务器的 `/var/www/fba_ui/` 目录下
---
---
url: /fastapi_best_architecture_docs/frontend/summary/arco.md
---
# Arco Design Pro 实验性实施
我们已于 2025 年 3 月 29 日对 Arco 仓库进行封存,此后它将不再接收任何更新。尽管做出这一决定让我们心生不舍,毕竟 Arco
曾承载了我们无数的探索与期待,但技术的脚步永不停歇,为了顺应更高效、更前沿的发展需求,我们不得不迈向新的篇章。
至此,承蒙每一位大佬的厚爱,请与我们携手共进,打开 [Vben Admin Antd](intro.md) 新篇章
::: note
此实施内部通过硬编码实现了 Casbin RBAC 鉴权,如需解耦,需手动删除 Casbin、API 管理及其所有调用
:::
::: caution
此实施自 v1.0.4 版本起,正式宣告其使命完结,fba 后续版本将不再对此进行适配,请不要将其用于生产!
:::
---
---
url: /fastapi_best_architecture_docs/frontend/summary/intro.md
---
# 介绍
基于 Vben Admin Antd 构建的 fastapi\_best\_architecture 前端完整版实施
::: warning
fba 从始至终一直是企业级后端架构解决方案,并没有针对前端的专项计划,前端项目只是一项附加产物
我们的团队中没有专业的前端工程师,如果您都此项目的发展和实施有更好的见解,请直接创建 Issues 或 PR
:::
::: info
如果您愿意为此负责,担任维护人员,随时欢迎提交申请
[**申请加入团队**](./join.md){.read-more}
:::
---
---
url: /fastapi_best_architecture_docs/frontend/summary/quick-start.md
---
# 快速开始
::: caution
前端已默认集成【字典】功能,所以 fba 必须安装字典插件(已内置)并执行插件中的 SQL 脚本
:::
::: steps
1. 准备本地环境
* Node.js(20.15.0 及以上版本)
2. 拉取 Git 仓库
```shell
git clone https://github.com/fastapi-practices/fastapi_best_architecture_ui.git
```
3. 安装依赖
```shell
pnpm install
```
4. 启动
```shell
pnpm dev
```
:::
---
---
url: /fastapi_best_architecture_docs/group.md
---
# 交流群
[通过 fba 作者主页与他互动](https://wu-clan.github.io/homepage/){.read-more}
## Discord
Discord 社区是我们的开发技术交流平台,这是一个充满活力的开源社区群组,欢迎来自全球的开发者、爱好者和用户。在这里,
大家可以自由分享想法、讨论技术、协作项目,或是获取最新的更新与支持。加入我们,一起参与这场开源之旅吧!
:::center
点击加入
:::
## 微信群
对于需要提供大量源码或截图的问题,建议通过 Discord 进行提问
---
---
url: /fastapi_best_architecture_docs/join.md
---
# 加入团队
[FastAPI Practices](https://github.com/fastapi-practices) 及其生态系统的成长离不开开源社区的支持,如果您喜欢我们的产品并愿意参与其中,我们将不胜荣幸。
我们会根据您的 PR 和参与度作为评估标准,诚邀您加入我们的 [团队](https://github.com/orgs/fastapi-practices/people)
,或将您的信息添加到我们的 [官网](./team.md)。如果您对此有意向,请通过 Discord 与我们联系,并提供以下信息(可直接复制并填写)
```
**昵称:** xxx
**个人描述:** xxx
**GitHub 链接:** xxx
**城市坐标:** 城市+省/直辖市
**个人主页:** xxx(默认为 GitHub 链接)
**PR 链接:** xxx(如果有)
```
---
---
url: /fastapi_best_architecture_docs/marketplace.md
---
# 插件市场
---
---
url: /fastapi_best_architecture_docs/open-source.md
---
# 官方开源
在此之前,让我们通过维基百科简单了解下 [开源](https://zh.wikipedia.org/wiki/%E5%BC%80%E6%BA%90%E8%BD%AF%E4%BB%B6) 这个词
---
---
url: /fastapi_best_architecture_docs/plugin/before.md
---
# 前言
::: warning
为了维护您的个人权益,在开始使用插件之前,请务必仔细阅读完此文档
:::
## 愿景
提供一个共创平台,告别高耦合集成,让功能变得像乐高一样随意拼装
遗憾的是,我们并不会提供插件管理平台对插件进行统一管理,我们计划将所有插件在 [插件市场](../marketplace.md) 进行展示和导航
## 开发
请移步至 [插件开发](dev.md)
## 收费吗
取决于插件开发者
## 是否提供源码
取决于插件开发者
## 可商用吗
取决于插件开发者
## 技术支持
需自行联系插件开发者
## 免责声明
* 对于使用恶意插件程序造成的损失,我们无需承担任何责任
* 对于付费插件作者跑路行为,我们无需承担任何责任
---
---
url: /fastapi_best_architecture_docs/plugin/dev.md
---
::: info
在官方仓库中,包含多个内置插件,位于 `backend/plugin` 目录下,结合官方仓库阅读此文档,效果更佳
:::
## 后端
::: steps
1. 拉取最新的 fba 项目到本地并配置好开发环境
2. 通过 [插件类型](#插件类型)、[插件路由](#插件路由)、[数据库兼容性](#数据库兼容性) 了解插件系统的运作机制
3. 根据 [插件目录结构](#插件目录结构) 进行插件开发
4. 完成插件开发
5. [插件分享](./share.md)
:::
### 插件类型
::: tabs#plugin
@tab 应用级插件
在 [项目结构](../backend/summary/intro.md#项目结构) 中,app
目录下的一级文件夹被视为应用,此原理同样应用于插件系统。
此类插件会像应用一样被注入到系统中,我们称这类插件为【应用级插件】
@tab 扩展级插件
此类插件会被注入到 app 目录下已存在的应用中,我们称这类插件为【扩展级插件】
:::
### 插件路由
如果插件符合插件开发的要求,则插件中的所有路由都将自动注入到 FastAPI 应用中。但值得注意的是,启动时间可能会随着插件数量的递增而增加,因为
fba 会在每次启动前对所有插件进行实时解析
::: tabs#plugin
@tab 应用级插件
应完全遵循 [路由结构](../backend/reference/router.md#路由结构) 进行开发
@tab 扩展级插件
必须将应用中的 api 目录结构进行 1:1 复制,可参考 fba
中的内置插件 [notice](https://github.com/fastapi-practices/fastapi_best_architecture/tree/master/backend/plugin/notice/api)
:::
### 数据库兼容性
fba 内所有官方实现都同时兼容 mysql 和 postgresql,但我们不对第三方插件进行强制要求,如果您对此感兴趣,请查看 SQLAlchemy 2.0
官方文档:[TypeDecorator](https://docs.sqlalchemy.org/en/20/core/custom_types.html#typedecorator-recipes)、
[with\_variant](https://docs.sqlalchemy.org/en/20/core/type_api.html#sqlalchemy.types.TypeEngine.with_variant)
### 插件目录结构
插件统一放置在 `backend/plugin` 目录下,以下是插件的目录结构
::: file-tree
* xxx 插件名
* api/ 接口
* crud/ CRUD
* model 模型
* **init**.py 在此文件内导入所有模型类
* …
* schema/ 数据传输
* service/ 服务
* sql 如果插件需要执行 SQL 则建议
* mysql
* init.sql 自增 id 模式
* init\_snowflake.sql 雪花 id 模式
* postgresql
* init.sql 自增 id 模式
* init\_snowflake.sql 雪花 id 模式
* utils/ 工具包
* .env.example 环境变量
* **init**.py 作为 python 包保留
* … 更多内容,例如 enums.py...
* plugin.toml 插件配置文件
* README.md 插件使用说明和您的联系方式
* requirements.txt 依赖包文件
:::
### 插件配置
`plugin.toml` 是插件的配置文件,每个插件都必须包含此文件
::: tabs#plugin
@tab 应用级插件
```toml
# 插件信息
[plugin]
# 图标(插件仓库内的图标路径或图标链接地址)
icon = 'assets/icon.svg'
# 摘要(简短描述)
summary = ''
# 版本号
version = ''
# 描述
description = ''
# 作者
author = ''
# 标签
# 当前支持:ai、mcp、agent、auth、storage、notification、task、payment、other
tags = ['']
# 数据库支持
# 当前支持:mysql、postgresql
database = ['']
# 应用配置
[app]
# 路由器最终实例
# 可参考源码:backend/app/admin/api/router.py,通常默认命名为 v1
router = ['v1']
# 代码中的配置项(全大写)
# 该配置项为可选,详情请查看:热插拔
[settings]
XXX = X
```
@tab 扩展级插件
```toml
# 插件信息
[plugin]
# 图标(插件仓库内的图标路径或图标链接地址)
icon = 'assets/icon.svg'
# 摘要(简短描述)
summary = ''
# 版本号
version = ''
# 描述
description = ''
# 作者
author = ''
# 标签
# 当前支持:ai、mcp、agent、auth、storage、notification、task、payment、other
tags = ['']
# 数据库支持
# 当前支持:mysql、postgresql
database = ['']
# 应用配置
[app]
# 扩展的哪个应用
extend = '应用文件夹名称'
# 接口配置
[api.xxx]
# xxx 对应的是插件 api 目录下接口文件的文件名(不包含后缀)
# 例如接口文件名为 notice.py,则 xxx 应该为 notice
# 如果包含多个接口文件,则应存在多个接口配置
# 路由前缀,必须以 '/' 开头
prefix = ''
# 标签,用于 Swagger 文档
tags = ''
# 代码中的配置项(全大写)
# 该配置项为可选,详情请查看:热插拔
[settings]
XXX = X
```
:::
### 全局配置
fba 采用全局单配置文件(类似 Django),我们的标准做法是在 `backend/core/conf.py` 中统一添加插件的全局配置,示例如下:
```python
##################################################
# [ Plugin ] email
##################################################
# .env
EMAIL_USERNAME: str
EMAIL_PASSWORD: str
# 基础配置
EMAIL_HOST: str
EMAIL_PORT: int
EMAIL_SSL: bool
EMAIL_CAPTCHA_REDIS_PREFIX: str
EMAIL_CAPTCHA_EXPIRE_SECONDS: int
```
整个结构分为【插件配置说明注释】、【插件环境变量配置及注释】、【插件基础配置及注释】,但是,在发布的插件中,我们无法添加这些配置,只能通过
`README` 进行说明,提醒用户如何完成插件全局配置,可参考 fba 官方插件:[oss](https://github.com/fastapi-practices/oss)
::: caution
全局配置默认使用最高优先级赋值,优先级如下:
```mermaid
graph LR
System("系统环境变量") --> DotEnv[".env"]
DotEnv --> Settings["conf.py"]
Settings --> Plugin["插件 settings 配置项"]
```
:::
### 热插拔
从 ==v1.13.0=={.warning} 开始,按以下要求进行配置,将自动适配热插拔特性
* 插件环境变量
如果插件需要添加环境变量,则需在插件根目录添加 `.env.example` 文件,并添加环境变量配置,参考如下:
```dotenv:no-line-numbers
# [ Plugin ] email
EMAIL_USERNAME: str
EMAIL_PASSWORD: str
```
* 插件基础配置
如果插件需要添加基础配置,则需在 [插件配置](#插件配置) 中的 `settings` 配置项中添加基础配置,参考如下:
::: warning
`plugin.toml` 和 `backend/core/conf.py` 中的配置方式完全不同。请格外注意,避免混淆
:::
```toml:no-line-numbers
[settings]
EMAIL_HOST = 'smtp.qq.com'
EMAIL_PORT = 465
EMAIL_SSL = true
EMAIL_CAPTCHA_REDIS_PREFIX = 'fba:email:captcha'
EMAIL_CAPTCHA_EXPIRE_SECONDS = 180 # 3 分钟
```
完成以上配置后,如果插件无需更多修改,通过 [CLI 或 Git](./install.md) 方式安装插件后,将无损适配热插拔
::: tip
除此之外,我们仍强烈建议您在开发阶段添加 [全局配置](#全局配置),并在发布的插件 README 中添加全局配置说明,如果你和你的插件用户想通过
IDE 获取全局配置键入提示,这是必需的,相反,你们将无法获取 IDE 键入提示
:::
## 前端
::: steps
1. 拉取最新的 fba\_ui 项目到本地并配置好开发环境
2. 根据 [插件目录结构](#插件目录结构-1) 进行插件开发
3. 完成插件开发
4. [插件分享](./share.md)
:::
### 插件目录结构
插件统一放置在 `apps/web-antd/src/plugins` 目录下,以下是插件的目录结构
::: file-tree
* xxx 插件名
* api 接口
* index.ts
* langs 多语言
* en-US
* 插件名.json
* zh-CN
* 插件名.json
* routes 路由
* index.ts
* views 视图
* index.vue
* …
* … 更多内容
:::
## 注意事项
::: caution
非必要情况下,插件代码中尽量不要引用架构中的现有方法,如果架构中的现有方法发生变更,则插件也必须同步变更,否则插件将被损坏
:::
---
---
url: /fastapi_best_architecture_docs/plugin/install.md
---
# 插件安装
## 后端
:::: tabs
@tab CLI
1. 通过在命令行输入 `fba add -h` 获取相关信息
2. 通过 `fba add` 命令进行安装
3. 根据插件说明(README.md)进行相关配置
4. 重启服务
@tab GIT
1. 获取插件 git 仓库地址,理论上支持任何平台(GitHub、Gitlab、Gitee、Gitea...)
2. 通过 fba git 插件安装接口进行安装
3. 根据插件说明(README.md)进行相关配置
4. 重启服务
@tab ZIP
1. 获取打包好的插件 zip 压缩包
* 下载插件仓库为 zip 压缩包
::: details GitHub 示例
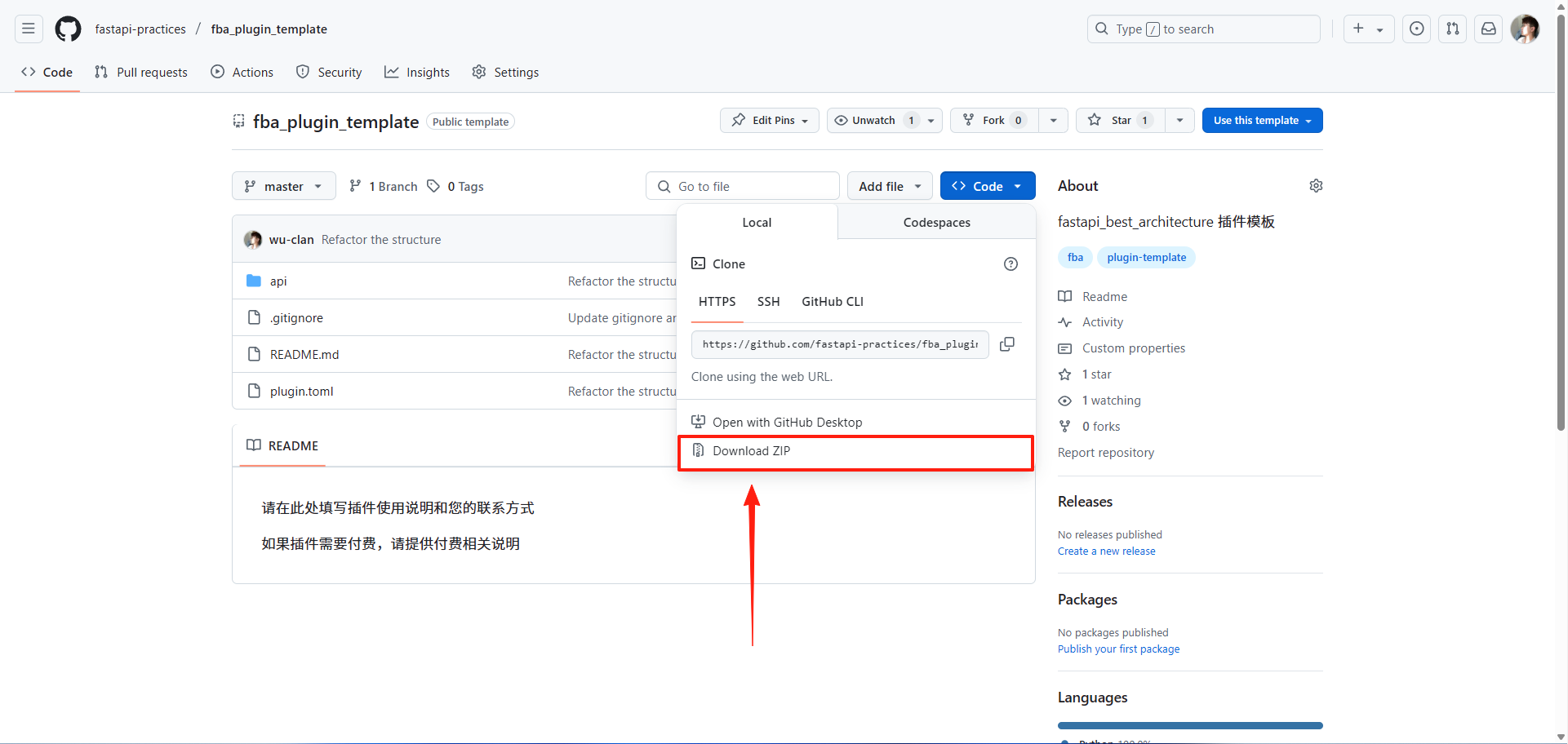
:::
* 通过 fba 插件下载接口下载的 zip 压缩包
2. 将 zip 压缩包通过 fba zip 插件安装接口进行安装
3. 根据插件说明(README.md)进行相关配置
4. 重启服务
@tab 手动
1. 获取插件仓库源码并下载
2. 将下载的源码文件夹直接拷贝到 `backend/plugin` 目录下
3. 根据插件说明(README.md)进行相关配置
4. 重启服务
::::
::: warning 私有仓库
对于私有仓库,需要将 Token 嵌入 URL 中进行认证:`https://@github.com/username/private-repo.git`
:::
## 前端
1. 获取插件仓库源码并下载
2. 将下载的源码文件夹直接拷贝到 `apps/web-antd/src/plugins` 目录下
3. 重启服务
---
---
url: /fastapi_best_architecture_docs/plugin/share.md
---
# 插件分享
想要将插件与他人分享,您必须为此创建一个公开的 Github 仓库
## 后端
::: warning 插件仓库命名规则
`插件仓库名 == 插件名`
假如插件仓库命名为 `sms`,安装此插件后,`backend/plugin` 目录下就会新增一个 `sms` 文件夹
插件总是独一无二的,不允许安装同名插件,所以在对插件进行命名时,应尽量保持其独特性,否则将导致插件冲突
:::
:::: steps
1. 创建个人插件仓库
::: details 使用 [fba\_plugin\_template](https://github.com/fastapi-practices/fba_plugin_template) 创建个人插件仓库
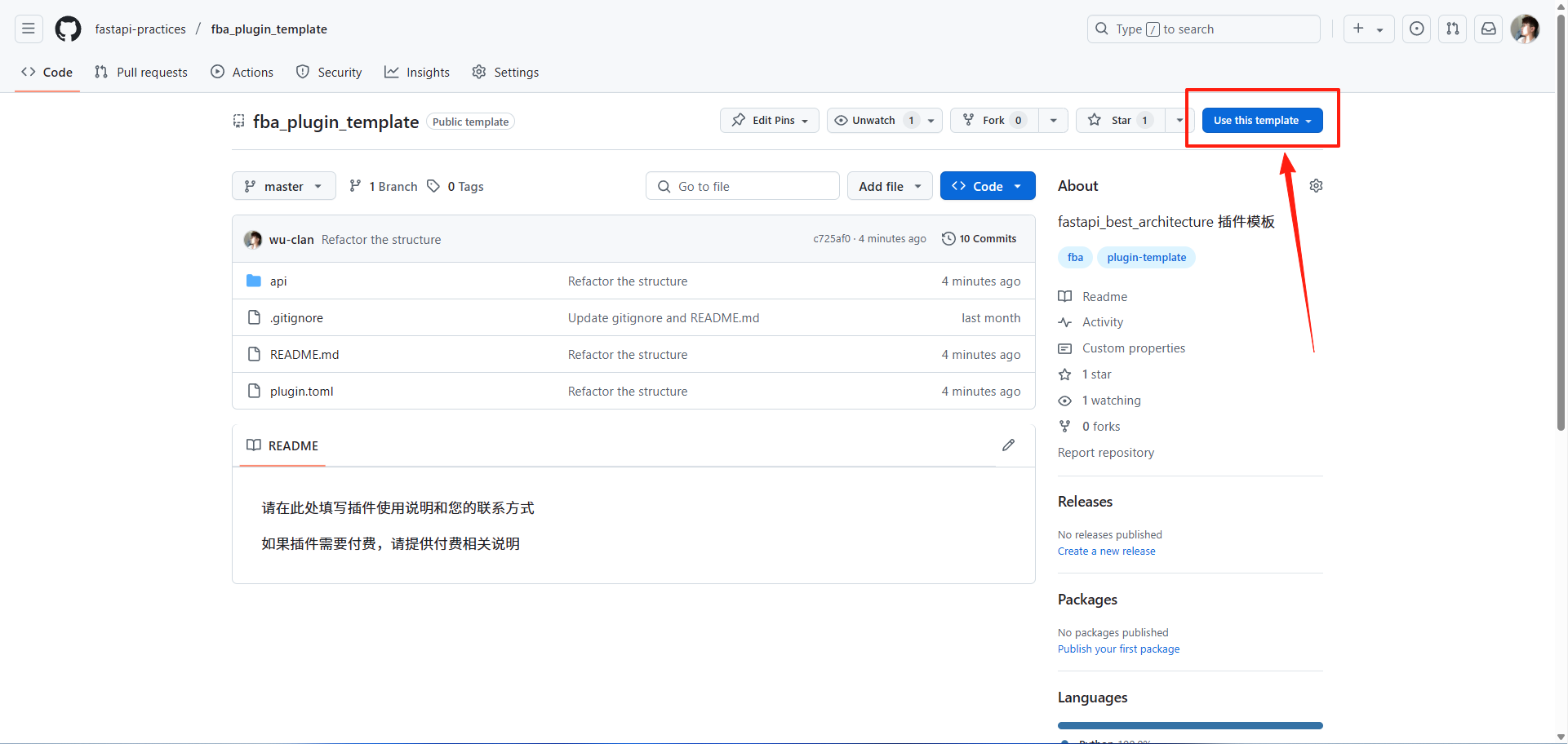
:::
2. 上传代码
将在 fba 中开发好的所有插件代码拷贝到个人插件仓库中
::: caution
应拷贝插件目录中的所有文件,而不是拷贝插件目录
:::
::::
## 前端
::: warning 插件仓库命名规则
\==为了区分 UI 插件,我们需要为插件仓库名添加 `_ui` 后缀=={.important}
`插件仓库名_ui == 插件名_ui`
假如插件仓库命名为 `sms_ui`,安装此插件后,`apps/web-antd/src/plugins` 目录下就会新增一个 `sms_ui` 文件夹
插件总是独一无二的,不允许安装同名插件,所以在对插件进行命名时,应尽量保持其独特性,否则将导致插件冲突
:::
:::: steps
1. 创建个人插件仓库
使用 [fba\_ui\_plugin\_template](https://github.com/fastapi-practices/fba_ui_plugin_template) 创建个人插件仓库
2. 上传代码
将在 fba\_ui 中开发好的所有插件代码拷贝到个人插件仓库中,仅限 [Vben Admin Antd](../frontend/summary/intro.md) 工程
::: caution
应拷贝插件目录中的所有文件,而不是拷贝插件目录
:::
::::
## 发布插件
要想发布插件,你需要为 fba 插件 github 仓库创建一个 PR.
:::: steps
1. Fork 仓库
[进入 fba 插件 github 仓库](https://github.com/fastapi-practices/plugins),将仓库 fork 到个人账户
2. 克隆仓库
```shell
# 将地址替换为上面 fork 的仓库地址
git clone https://github.com/your-username/plugins.git
```
3. 创建分支
```shell
# 注意替换 add-your-plugin-branch
git checkout -b add-your-plugin-branch
```
4. 扩展子模块
```shell
# 注意替换 your-username、your-plugin-name
git submodule add https://github.com/your-username/your-plugin-name.git plugins/your-plugin-name
git add plugins/your-plugin-name
```
::: warning
所有扩展子模块必须使用 HTTPS URL,而不是 SSH URL(git@github.com)
:::
5. 提交和推送
```shell
# 注意替换 your-plugin-name
git commit -m "Add your-plugin-name plugin"
```
```shell
# 注意替换 add-your-plugin-branch
git push --set-upstream origin add-your-plugin-branch
```
6. PR
通过 GitHub 创建 PR
7. 合并
fba 团队将尽快完成检查,一旦您的 PR 合并,插件将被发布到 [插件市场](../marketplace.md)
::::
## 更新插件
要想更新插件,你需要为 fba 插件 github 仓库创建一个 PR.
执行与发布相同的步骤,并更新以下行为:
* 更新步骤 4 中的命令
```shell
git submodule update --remote plugins/your-plugin-name
git add plugins/your-plugin-name
```
* 更新步骤 5 中的提交信息,现在已不再是新增,而是更新
::: info
如果你想自动执行此过程,可以使用 [GitHub Action](https://github.com/fastapi-practices/plugin-release)
:::
---
---
url: /fastapi_best_architecture_docs/plugin/video.md
---
# 视频讲解
我们将通过此视频分别介绍 [插件开发](./dev.md)、[插件分享](./share.md)、[插件安装](install.md)
::: warning
此视频已过时,需等待重新录制
:::
@[bilibili](BV1qaoLYxEXi)
---
---
url: /fastapi_best_architecture_docs/pricing.md
---
# pricing
---
---
url: /fastapi_best_architecture_docs/privacy-policy.md
---
# 隐私政策
2.2 信息存储的地域
2.3 产品或服务停止运营时的通知
---
---
url: /fastapi_best_architecture_docs/questions.md
---
# 常见问题
## 2025.12 项目 Star 为何猛增
刷星?完全不存在,无论是何项目,我们坚决抵制这种无耻行为
原因?X 上面一位博主分享了此项目,原帖:[@tom\_doerr](https://x.com/tom_doerr/status/1995998190768648296?s=20)
## 返回数据跟数据库对不上
### 非首次部署或反复部署
若此前已调用过 fba 接口,相关数据可能已悄无声息地写入 Redis 缓存。随后,即便重新部署了 fba,整个部署过程并不会自动清除
Redis 中的缓存数据。
因此,调用重新部署后的 fba 接口时,若发现返回数据异常,而数据库检查又未发现问题,很可能是缓存未更新导致。此时,手动清理
Redis 中的 fba 缓存即可解决问题,系统将自动恢复正常
### 手动修改数据库数据
假设我们直接在数据库中修改了某些数据,但调用接口后发现返回结果未发生变化。返回数据可能来源于 Redis
缓存,而通过数据库直接修改的操作不会触发缓存的自动更新。
因此,返回数据看似未受影响。解决方法是手动清理 Redis 中的相关缓存,之后数据将正确反映修改结果
## Can't call await\_only() here
```json
{
"code": 500,
"msg": "(sqlalchemy.exc.MissingGreenlet) greenlet_spawn has not been called; can't call await_only() here. Was IO attempted in an unexpected place?\n[SQL: SELECT sys_dict_data.id AS sys_dict_data_id, sys_dict_data.label AS sys_dict_data_label, sys_dict_data.value AS sys_dict_data_value, sys_dict_data.sort AS sys_dict_data_sort, sys_dict_data.status AS sys_dict_data_status, sys_dict_data.remark AS sys_dict_data_remark, sys_dict_data.type_id AS sys_dict_data_type_id, sys_dict_data.created_time AS sys_dict_data_created_time, sys_dict_data.updated_time AS sys_dict_data_updated_time \nFROM sys_dict_data \nWHERE %s = sys_dict_data.type_id]\n[parameters: [{'%(2071788311008 param)s': 1}]]\n(Background on this error at: https://sqlalche.me/e/20/xd2s)",
"data": null,
"trace_id": "89afd9b0f2b8442590661701e2b6b495"
}
```
在 SQLAlchemy 2.0 中异步中,关系(relationship)表默认使用
[懒加载](https://docs.sqlalchemy.org/en/20/glossary.html#term-lazy-loading),所以,如果你未在 ORM 语句中添加关联字段的
加载策略,那么关联字段可能被定义为错误(如上图所示),此时如果调用 pydantic / fastapi 序列化,那么将触发字段错误,因为字段本身就是个错误
可用的解决方案有多种,请阅读 SQLA 官方文档,fba 默认使用 `noload()` 对此进行处理,例如:
```python
return await self.select_order( # [!code word:noload]
'id',
'desc',
load_options=[
selectinload(self.model.dept).options(noload(Dept.parent), noload(Dept.children), noload(Dept.users)),
selectinload(self.model.roles).options(noload(Role.users), noload(Role.menus), noload(Role.scopes)),
],
**filters,
)
```
## PostgreSQL 主键自增失败
当通过 sql 脚本执行插入数据后,由于 pg 特性,序列值不会与表中最大值同步,此时如果通过代码执行写入操作,可能触发
`DETAIL: Key (id)=(x) already exists` 的错误
解决方案请自行浏览器搜索:如何重置 pg 主键序列?
## 数据库时区陷阱
MySQL 不支持时区存储类型,而 PostgreSQL 拥有完美的时区类型,所以在数据库中存储时间列确实是一件令人头疼的事情,不过我们已为此实现完美方案,兼容
mysql 和 postgresql,[查看详情](./backend/reference/timezone.md#数据库)
---
---
url: /fastapi_best_architecture_docs/sponsors.md
---
# 成为 fba 的赞助者
自 fba
创建以来,我们一直致力于 [持续更新](https://github.com/fastapi-practices/fastapi_best_architecture/blob/master/CHANGELOG.md)
和 [积极维护](./backend/summary/why.md#长期维护),为此,我们投入了大量的时间和无限的热爱。感谢您为 fba
给予的大力支持,您的每份鼓励都将成为我们继续前进的动力
## 荣誉赞助
::: tip
请通过 [Discord](./group.md) 与作者联系并发送赞助截图,以获取专属身份标签
:::
## 展位赞助商
您可以 [联系作者](./group.md) 就展位的详细事宜与他进行沟通
::: warning 推广
选择【独家展位、特别展位】赞助,可帮助您的产品在 ==Discord社区== 和 ==微信交流群== 以公告的形式进行推广一次
* 优先推广和程序员相关的互联网产品,比如:低代码开发平台、网课、开发软件、云服务器、个人博客等等,实体产品如键盘、显示器、耳机等等,如果是和程序员无关的产品,可酌情考虑是否推广
* 拒绝接受违反法律法规、灰色相关的产品推广
公告消息如下:(您也可以提供自定义非政治、法律法规敏感推广词/图片)
```
感谢 xxx 老板对 fba 项目的慷慨赞助,以下是老板的产品,大家感兴趣的可以关注一下:
xxx 商品名称
链接:https://xxx.xx
```
:::
::: caution
展位转化效果可能因市场环境、受众行为等多种因素影响,我们无法保证确切的转化结果
:::
## 注意事项
> \[!CAUTION]
> 由于当前所有赞助均为自愿支持性质,我们暂时无法为您提供发票开具服务,对此带来的不便深表歉意。
>
> 您的每一份支持都是我们持续前进的动力,期待未来能以更完善的方式回馈您的信任。若需进一步沟通,欢迎随时联系
---
---
url: /fastapi_best_architecture_docs/stack.md
---
# 技术栈
fba 采用当前主流技术框架,我们追求新事物,拥抱新事物,并且积极更新与跟进
技术框架采用基准取决于项目的流行度、活跃度、答复效率以及维护周期等
## 后端
## 前端
---
---
url: /fastapi_best_architecture_docs/team.md
description: >-
FastAPI Practices 及其生态系统发展的背后是一个由开源社区人员组成的团队,我们对团队中的任何成员以及所有的关注者都致以崇高的敬意;
我们欢迎每一位开源伙伴的加入
---
# FastAPI Practices
[**申请加入团队**](./join.md){.read-more}
---
---
url: /fastapi_best_architecture_docs/users.md
---
# 用户登记
::: important
\==这个项目有人在生产环境中使用吗?=={.important}
如果您/您所在的企业/组织使用了 fba
进行项目开发,我们诚挚的邀请您参与:[用户登记](https://github.com/fastapi-practices/fastapi_best_architecture/issues/477)
:::